gojqのパーサーを書き直しました
jqはJSONを絞り込むツールですが、実はれっきとしたプログラミング言語です。
算術演算子、論理演算子、分岐構文、try・catch、そして関数定義があり、ループは再帰関数で実装します。
単に .foo とか .[0] とかでJSONを辿るだけのツールだと思われている方は、builtin関数の定義を見ていただくと良いかと思います。
selectやmapのように、よく使われる関数でさえ内部実装になっていない (Cで書かれていない) のは面白いですね。
jqのクエリを思ったように書けないという経験から、jqをより深く知るためにGo言語で再実装したのがgojqです。 去年の4月から開発を始め、8月にブログ記事を書きました。 jqのほぼすべての機能を実装しており、pure Goで書かれているのでGo言語のツールに簡単に組み込むことができます。
この記事公開以降も開発を続けています。
--arg,--argjsonの実装- YAML入出力オプションの実装
- モジュールファイルの読み込みの実装
input,inputs関数の実装try,catchと|=演算子を組み合わせたときのバグ修正- これはjq 1.6でもバグっている問題で、
jq -nc '{"x": "10"} | map_values(tonumber? // .)'は{"x":10}にならないといけない
- これはjq 1.6でもバグっている問題で、
- ライブラリー用途の改善 (context対応・ドキュメントの充実)
- 実行ファイルのサイズ改善 (v0.9.0: 7.86MiB, v0.10.4: 6.45MiB)
順調に機能開発が進んでいるように見えます。 しかしjqとの差異が小さくなるにつれて、徐々にクエリのパーサーに不満が出てきました。 パーサーは機能とは違ってユーザーからは直接は見えない場所ですから、どう実装しても自由なはずです。 逆に言うと、ユーザーへの大きなメリットでもなければ書き直そうとはなりません。 それでも書き直さなければならないほどの理由がありました。
gojqの開発当初より使っていたparticipleというライブラリーの紹介をします。 participleというのはGo言語でパーサーを作るためのライブラリーです。 LL(k)の文法をパースできます。
例えば、次のように構造体のタグに構文を書いてみます。
type Value struct { Object *Object ` @@` Array *Array `| @@` Number string `| @Number` Str string `| @String` Null bool `| @"null"` True bool `| @"true"` False bool `| @"false"` } type Object struct { KeyVals []*ObjectKeyVal `"{" (@@ ("," @@)*)? "}"` } type ObjectKeyVal struct { Key string `@String ":"` Val *Value `@@` } type Array struct { Vals []*Value `"[" (@@ ("," @@)*)? "]"` }
あとはレキサー (lexer) を実装しておけば、JSONをパースすることができます。 trailing commaを許したいな (それはもうJSONではないけど) と思ったら以下の修正をするだけです。
type Object struct {
- KeyVals []*ObjectKeyVal `"{" (@@ ("," @@)*)? "}"`
+ KeyVals []*ObjectKeyVal `"{" (@@ ("," @@)*)? ","? "}"`
}
type Array struct {
- Vals []*Value `"[" (@@ ("," @@)*)? "]"`
+ Vals []*Value `"[" (@@ ("," @@)*)? ","? "]"`
}
このライブラリーはとても便利で、素早くパーサーを作り上げることができますし、文法の変更も簡単です。 暗黙的なルールは少なく、structの定義から目線を少し右に動かすだけで文法を理解できます。
gojqではjqクエリのパースにparticipleをずっと使ってきました (JSONのパースはencoding/jsonを使っています) が、つらいことがいくつかありました。
- 演算子の結合の強さを構造体によって解決する必要があるため、結合の強さの数だけ、構造体が深くなる
- これによってparse時の構造体初期化やコード生成時に構文木を辿るときにオーバーヘッドがある
- gojqはbuiltin関数を事前にパースしてコード生成してバイナリに含めているため、構造体が深いほど実行ファイルのサイズが大きくなる
- コマンド実行するたびにbuiltin関数をパースするのは避けたい (jqはそうなっている)
- パース時のパフォーマンスがyacc的なパーサーと比較すると遅い可能性がある
- リフレクションを使っている以上はそのオーバーヘッドは避けようがないし、このタイプのパーサージェネレータの中ではかなり頑張っている方であることは強調しておきます
- goyacc版を実際に作るまでは推測でしかなかったし、どれくらい遅いのかは検討もつかなかった
- 文字列補間 (string interpolation) のパースができない (参考)
- participleを使いつつ無理やり実装しようとして、内部の式も含めて文字列にマッチする正規表現を生成していたが、文字列補間のネスト数に制限があったし (
"\("\("\("\(1+2)")")")"のようなもの) 、実装も明らかにおかしかった。 participleを使ってパーサーを書き始めた頃はこのライブラリーだと文字列補間の実装ができないのに気がついていなかったし、そもそもjq言語に文字列補間があるのを知らなかった (気がする)。
- participleを使いつつ無理やり実装しようとして、内部の式も含めて文字列にマッチする正規表現を生成していたが、文字列補間のネスト数に制限があったし (
- jqがyaccを使っているので、その文法定義をLL(k)にわざわざ定義し直すのが面倒
実装当初から積み上げてきたパーサーを捨てる決断をするのにかなり時間がかかりました。 そもそも最初にparticipleを選んだもの、yaccのような枯れた手法ではなく、モダンなパーサーライブラリーを使いたいという気持ちがあったからです。 長大な生成ファイルを (go getのために) リポジトリに含めなくて良いのも好きな側面です。 しかし、文字列補間をはじめ、participleを使っているがゆえに実装が歪んでしまっている場所が増えてきて、耐えられなくなってしまいました。 そして先日、ようやく決心してgoyaccでのパーサー再実装を行いました。
すべてのテストケースが新しいパーサーで通るまで丸2日、文字列補間を正しく実装するのに1日、そしてconflictの修正やパフォーマンス改善などを行っていたので4, 5日くらいかかりました。 participleでパーサーを作るときの体験があまりに良かったのでyaccスタイルのパーサーは避けていたのですが、今回改めてgoyaccを使ってみたらこれも悪くはないなという感想になりました。
- participleを使っていたときは、ルールを手で書くなんて大変、participleはcoolと思っていたが、やってみたらそこまで大変ではなかった
- Goにはunionがないのでtype assertionする必要があって少し面倒なのは仕方ない
interface{}を使わない手もあるが、メモリーを多く使うのでおすすめはしない
- Goにはunionがないのでtype assertionする必要があって少し面倒なのは仕方ない
- 演算子の結合はgoyaccに任せられるので、構造体を浅くできて最高
- レキサーは手で書いたほうが良い
- 文字列補間があるならなおさらそう
- conflictを解決していたら大学時代を思い出した
文字列補間 (string interpolation) というのはパーサーを作る上でとてもおもしろいトピックです。 この機能があるかないかで、文字列をパースする難易度が大きく変わってきます。 JavaScript, Ruby, Python, Scala, C#など様々な言語がこの機能を備えています。
% node -e 'console.log(`${1 + 2}`)' 3 % ruby -e 'print "#{1 + 2}"' 3 % python -c 'print(f"{1 + 2}")' 3 % jq -nr '"\(1 + 2)"' 3 % node -e 'console.log(`${`${`${`${`${1 + 2}`}`}`}`}`)' 3 % jq -nr '"\("\("\("\("\(1 + 2)")")")")"' 3 % jq -nr '"foo \("bar" + "bar") \("\("baz" * 3)")"' foo barbar bazbazbaz
なぜこの文法のパースは難しいのでしょうか。 文字列補間のない言語の場合、レキサーは文字列を一つのトークンとして返すことができます。 おそらく、文字列トークンを表す正規表現を書くことができるでしょう。 しかし、文字列補間があると文字列自体が木になります。 文字列の中身をパースしているときは、空白文字をスキップしてはいけません。 文字列補間の中身に改行やコメントが入ることもあるでしょうし、ネストすることもできます。 そしてパースエラーが発生したときは、元のプログラムのコードでのオフセット位置を報告すべきです。 これらをきちんと実装するためには、やはりレキサーを手で書き、文字列の中身を丁寧に辿るのがよいと思います。
participleを使っていたときは正規表現で無理やり文字列のトークンを抜き出し、コード生成時に文字列補間を解釈していました。文字列補間がある場合は任意の文字列を表す正規表現はそもそも作ることができませんし (ネスト数を制限すればできるが奇妙な制約になる)、文字列補間内のクエリにシンタックスエラーがある場合に、その位置をユーザーに伝えるのが難しくなります。goyaccに乗り換えてようやく文字列補間をきれいに実装できたとき、このシンタックスをパースするときの「正しいやり方」を理解できました。
文字列補間の閉じトークンをどのように判別するかというのはおもしろい問題です。 私は当初、括弧の深さを計算し、文字列補完の中をたどっているときに、対応しない閉じ括弧が来たら文字列補間の閉じトークンを返すような実装をしていました。 しかしこれは全く不要でした。 他のシンタックスの綴じ括弧と文字列補間の閉じトークンは区別する必要はなく、閉じ括弧はそのまま返してしまえばよいという気付きがありました。 文字列補間の開きと閉じにそれぞれトークンを割り当てないといけないと考えてしまうと、レキサーが無駄に複雑になってしまいます。
パーサーを書き直したことで、速度も大幅に改善しました。
jq言語で書かれたソースコードのパースにかかる時間の比較です (participle版は最初計測ミスかと思いましたが合っていました)。
およそ30倍の速度改善を達成できました。
reflectionベースの実装なので多少はオーバーヘッドがあることは分かっていましたが、ここまで差がつくとは思っていませんでした。
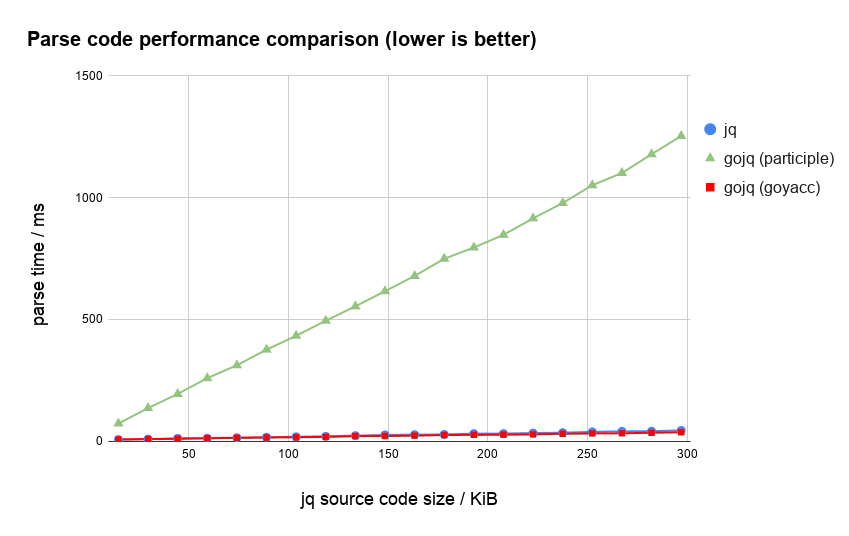
participle版のgojqを除いたグラフは次のようになります。 goyacc版のgojqは、jqと比較しても少し速くなっていることがわかります。
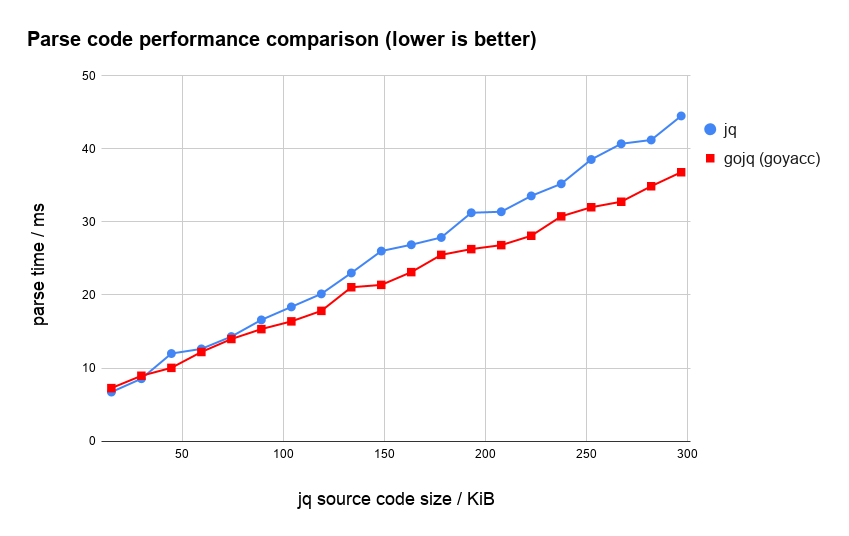
ソースコードをパースして終わりではありません。
jq言語には include 文がありますが、これはコード生成を行う必要があります。
以下のグラフは、パースとコード生成の両方を含む速度比較です。
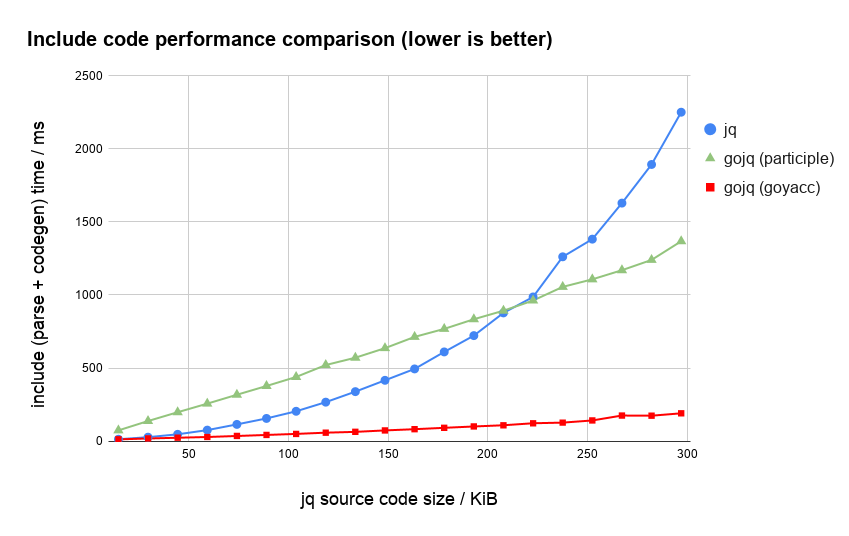
jqはソースコードのサイズが増えると急に遅くなっていきます。
試しにフィッティングしてみると、コードサイズに対して三乗で時間がかかっているようです。
まだ正確な理由は理解できていないのですが、jqの関数名解決のパフォーマンスは良くないようです (参考: block_bind_self)。
jqのパフォーマンス改善の余地が見つかったのでよかったです。
修正方法が分かりしだいパッチを投げようと思います。
別実装の存在によって本家の改善が進むというのはよくある話ですね。
実は、gojqでの「作り直し」は二回目になります。 初期の実装では再帰下降型の処理系で、これをコード生成して最適化を行うインタープリターに書き直しています。 そして今回パーサーも書き直したので、一番最初の設計は大外れということになるかもしれません。 ベストな設計というのは最初からはなかなかできませんね。 しかし、これまでの積み上げがあったからこそ (カバレッジの高いテストケース)、わずか数日でパーサーを入れ替えることができたのだと思います。 処理系の再実装と比べるとかなり簡単でした。
このような書き換えを行うときのコツは、テストを落とさないようにコミットしていきつつ、切り替えたときに通るテストの数を数えていくことだと思います。 例えばパーサーを入れ替えるときは、新パーサーで試してダメだったら旧パーサーにフォールバックするという処理にしておきます。 テストが落ちないように新パーサーを実装していくのです。 ただし、このやり方だとどれくらいの割合のテストが新パーサーで通るようになったかがわからないので、新パーサーに完全に切り替えたブランチを作っておいて、そちらにmergeしていきつつテストを回していくのです。 通るテストは徐々に増えていき、全てが通ったら旧パーサーを捨てることができます。
participleは、今までgojqの開発を大いに支えてくれました。 シンタックスの全容を把握できていない段階では、素早くパーサーを書き換えていける利点があるでしょう。 しかし、パーサーの扱える構文は限られており、無理にパースしようとすると大変なことになります。 また構文木とシンタックスが密結合だと様々な不具合が生じます。
yaccは古典的なツールですが、現代でも大いに活躍できるツールだと思います。 演算子の結合を宣言的に定義できるのはとても楽です。 生成されたパーサーの速度も魅力的です。 ちなみに今回goyaccを触って気になったところを修正するパッチを投げたら、すぐにレビューを頂いて次の日にはmergeしてくれました (cmd/goyacc: print newlines more consistently)。
gojqはv0.11.0で新しいフェーズに突入しました。 v0.10.4では6.45MiBあった実行ファイルのサイズを、4.91MiBまで削減することができました。 今回のリリースよりDocker Hubにもイメージを上げることにしました。 やるべきことは、まだまだあります。 パーサーはjqより少し速くなりましたが、処理系はjqよりも大幅に遅くなるクエリが存在することが分かっています。 gojqとの旅はもう少し続きそうです。