PDFのファイル構造を理解すると、テキストエディタでも直接PDFファイルを作ることができるようになります。このエントリーではPDFファイルの基礎要素を説明し、簡単なPDFファイルを例にしてファイル構造を説明します。更に、テキストを渡すとPDFファイルを吐いてくれる簡単なプログラムや、PDFを読み込んで簡単な解析をするプログラムを書いてみます。
目次
まえがき
1990年代前半、アドビシステムズは、どのプラットフォームやデバイスでも文書を確実に表示・共有できることを目的としてPDFファイルフォーマットを開発しました。
PDFの表示ソフト (Acrobat Reader、現在はAdobe Reader) が無償で配布されるようになると次第に人気を集め、今となっては、PDFは最も頻繁にやりとりされるファイルフォーマットの1つとして、確固たる地位に登りつめました。
官公庁や教育機関における資料や報告書、企業の発表資料、雑誌や書籍への入稿、広告会社におけるファイルのやりとり、学会でのプレゼンテーション、論文、標準規格の仕様書など、PDFファイルフォーマットの用途は多岐にわたります。
PDFファイルの仕様はアドビシステムズより公開されておりますし、ISO 32000-1:2008として国際規格化されています。
アドビシステムズが、1993年にPDFファイルの仕様を公開し、PDFファイルの読み書きするソフトの公開や販売を制限しなかったことが、今日のPDFファイルの人気に繋がっていると言ってもよいでしょう。
しかし、PDFファイルの仕様書は大きく、素人が勉強するには理解しやすいものではありません。
エンジニアの中でも、PDFファイルに対して積極的に興味を持つ人はほとんどいません。
PDFファイルはバイナリファイルであり、適当なエディタで開いても謎のバイナリ列が表示されるだけということも、「よし、理解しよう」という気にならない原因となっていると思います。
このエントリーでは、PDFのファイル構造を理解するための基礎的な内容を丁寧にお伝えしたいと思います。
PDFファイルに興味があるが、どこから手を付ければいいかわからない人や、PDFファイルをエディタで直に書けるようになりたい人、あまり興味はないけどPDFのファイル構造がどうなっているか雰囲気でも掴みたい人など、どんな人でも歓迎です。
PDFは数限られたソフトが出力することを許された闇に満ちたバイナリフォーマット?いいえ、全く違います。
ある程度単純なPDFなら、ほんの100行程度のコードで生成できるのです。
このエントリーは、次の書籍を元に書いています。
PDFについて全くの初心者だった私が手にしたこの書籍は、PDFファイルの基本的な用語や定義を丁寧かつ正確に解説した上で、サンプルを交えながらPDFの構造について説明しています。
私のこの記事でPDFファイルに興味を持たれた方は、書籍の購入をお薦めします。
PDFの仕様はISO 32000-1:2008にて定義されており、ISO標準となっています。
ISOのドキュメントの入手にはお金がかかりますが、アドビシステムズはISOに認証された仕様書のコピーを無料で公開しています。
PDF Reference and Adobe Extensions to the PDF Specification | Adobe Developer Connection
750ページもあって全て読むのは大変ですが、丁寧に書かれていて、なんといっても正確です。
この記事でPDFに興味を持たれた方や、PDFを扱うソフトウェアを書く場合は参考にしてください。
このドキュメントを、以下では『仕様書』として扱います。
それでは、PDFのファイル構造を理解する旅を、共に始めましょう。
オブジェクト
プログラミング言語の基礎を勉強するとき、まずはその言語で使える数字や文字列、変数や関数の理解から始めますよね。
PDFファイルでもその構造を成す基礎要素を理解することが、まず初めの第一歩となります。
PDFファイルの基礎要素は「オブジェクト」と呼ばれ、boolean、null、数字、文字列、名前、配列、辞書、そしてストリームがあります。
まずは、PDFのオブジェクトを順番に見て行きましょう。
PDFにはbooleanがあります。
true
false
小文字で表します。
JavaScriptやRubyなどと同じです。
PDFにはnullがあります。
null
小文字で表します。
PDFの数字には整数と実数があります。
例えば整数は次のようなものです。
10
250
0
-320
+25
上のように符号 (+/-) もつけることができます。
実数は次のようなものです。
10.5
3.14
-.05
+.0
指数表記 (例えば6.02e23といったもの) は許されていません。
文字列は、ダブルクォート"やシングルクォート'ではなく、丸括弧で囲って表します。
これは他の言語からするとやや異色ですね。
(Hello, world!)
他の言語においてダブルクォートで文字列を表現するときに、文字列の中のダブルクォートをエスケープしますよね: "He said, \"Hello, world.\""。
同様に、PDFの文字列の中の丸括弧は、エスケープします。
(Hello \(world\))
エスケープ文字自身も、エスケープします。
ただし、丸括弧が対応しているときは、エスケープしてもしなくても構いません。
(Hello (world). Escape character is \\. Open parenthesis is \(.)
丸括弧はしばしば対応して出てくるので、PDFファイルを直に書いているときは特にエスケープする必要はないでしょう。
しかし、プログラムで対応する括弧を調べるのは面倒なので (ネストしている可能性もあります)、丸括弧は常にエスケープする処理のほうが、PDF生成プログラムを書きやすいでしょう。
文字列の表現の仕方にはもう1通りあります。
16進数で表現する方法です。
例えば、abc あいうという文字列をSJISで表すと
$ echo -n "abc あいう" | iconv -f UTF-8 -t SJIS | xxd -p
6162632082a082a282a4
$ echo 6162632082a082a282a4 | xxd -r -p | iconv -f SJIS -t UTF-8
abc あいう
のようになります (端末のエンコーディングがUTF-8であることを仮定しています) ので、PDFの中でSJISエンコーディングでabc あいうという文字列を表現すると
<6162632082a082a282a4>
となります。
不等号 < 〜 > の中に、スペース無しの16進数表現で記述します。
この不等号の中でのスペースや改行は無視されます。
別にSJISエンコーディングでなくても構いません。
例えばUTF-16BEエンコーディングだと、
$ echo -n "abc あいう" | iconv -f UTF-8 -t UTF-16BE | xxd -p
0061006200630020304230443046
ですので、UTF-16BEエンコーディングでabc あいうを表す文字列は
<0061006200630020304230443046>
となります。
つまり、このリテラルだけではこれを解釈するためのエンコーディングは分からない、どういう文字列がエンコードされたものかは分からないということです。
文字列のエンコーディングを指定する方法は、日本語の扱い方にて詳しく扱います。
PDFには「名前」と呼ばれる、他の言語にはない特別な要素があります。
「名前」は、スラッシュ / から始まります。
/Type
/Pages
/Size
/Resources
/example
/@foo@bar_baz-baa
Rubyのシンボルリテラル (:test) に少し似ています。
スペース (' ' = '\x20') のように、'!' ('\x21') から'~' ('\x7e') の範囲外の文字は、#から始まる16進数表現で書かなくてはいけません。
また、番号記号 ('#' = '\x23') 自身は、#23のように表します。
/foo#20bar#23baz
これは foo bar#baz という名前を表しています。
名前は大文字と小文字を区別します。例えば /Type と /type は別の名前です。
そして、PDFには配列があります。
配列は、どんなオブジェクトも持つことが出来ます。
他の多くの言語にはカンマ区切りで配列を表しますが、PDFの配列にはカンマはありません。
[0 0 595 842]
配列には、種類の異なる様々な要素を持つことが出来ます。
[10 /Test (foo bar) [10 20]]
上記は、数字の10、名前の/Test、文字列の(foo bar)、そして配列[10 20]から成る配列を表しています。
PDFには「辞書」があります。辞書のキーは常に「名前」で、値はあらゆるオブジェクトが可能です。
辞書は << 〜 >> に囲んで表します。辞書の表記に : や , などは不要です。
<<
/foo /bar
/boo true
/baz <<
/hoge [/huga /huee]
>>
/arr [0 10 20]
>>
この辞書は、/fooを名前/barに、/booをbooleanのtrueに、/bazを辞書に、/arrを配列[0 10 20]に対応させています。
PDFの表記は一見奇妙でも、だいたい他の言語の要素と対応付けることが出来ます。
例えば、上記の辞書は次のJSONと概ね同じです。
{
"/foo": "/bar",
"/boo": true,
"/baz": {
"/hoge": ["/huga", "/huee"]
},
"/arr": [0, 10, 20]
}
PDFにおける「名前」はJSONにはありませんから便宜上文字列で表しましたが、「概ねのイメージ」では上のような感じに思って頂いて大丈夫です。
上のようなイメージで改めてpdfファイルの辞書を見ると、 << 〜 >> といったおかしな記号は使っているものの、次第に見慣れてくると思います。
PDFは「ストリーム」があります。ストリームは、バイナリ列と、そのバイナリ列に関する情報の辞書の組です。例えば、次の例ではHello, world!という文字を表示するというバイナリ列 (実質的にはアスキー文字列) と、その長さを表す辞書 << /Length 59 >> (上のJSONの例えで言うと { "/Length": 59 } です) から成っています。
<<
/Length 59
>>
stream
1. 0. 0. 1. 50. 700. cm
BT
/F0 32. Tf
(Hello, world!) Tj
ET
endstream
ストリーム辞書には/Lengthが必須項目です。
ストリームの本体は、streamとendstreamの間に記述します。
本体をどのように記述すればいいかは、後で詳しく説明します。
ストリームはしばしば圧縮されますが、このエントリーではストリームの圧縮については扱いません (ストリーム辞書の/Filterによって、ストリームの圧縮方法を指定します。既存のPDF文書を見る時の手がかりにしてください) 。
PDFの基本要素は以上です。逆に言うと、他の言語には普通にあるもの、例えば分岐、繰り返しや関数などはありません。
まとめると、PDFのオブジェクトは以下の8種類です。
- boolean (例:
true, false)
- null (例:
null)
- 整数・実数 (例:
10, -320, 3.14)
- 文字列 (例:
(Hello, world!), <616263>)
- 名前 (例:
/Type, /Pages)
- 配列 (例:
[10 /Test (foo bar) [10 20]])
- 辞書 (例:
<< /foo /bar /arr [0 10 20] >>)
- ストリーム (例:
<< /Length 59 >> stream ... endstream)
これらは全てオブジェクトです。リテラルもオブジェクトです。辞書も、配列も、文字列も、数字もnullもtrueもfalseも全部オブジェクトです。
この章の最後に、コメントについて説明します。
PDFにおけるコメントを表す文字は%です。
文字列やストリームの外で%があると、その場所から行末までがコメントになります。
4 0 obj
<<
/Test /Foo
>>
endobj
5 0 obj
(test % This is not a comment!)
endobj
PDFを扱うプログラムがコメントに書かれた内容を保存するとは限りません。
つまりPDFのユーザーに何かを伝える目的でコメントを書くことは全く意味がありません。
ただし、どんなPDFファイルにも存在し、かつPDFのファイル構造にとって特別なコメントが2つあります。
1つ目はこれです。
PDFファイルの先頭には必ずこの行があります。
1.NはPDFのバージョンを表し、現在Nには0から7までの値を使うことが出来ます。
2つ目はこれです。
%%EOF
PDFファイルの最後に必ず書かれています。
これらについてはファイル構造の章でもう少し詳しく説明します。
間接参照
PDFには、オブジェクトに番号をつけて、それを参照する仕組みがあります。
「間接参照 (indirect reference)」と呼ばれます。
あえて他の言語で言えば変数に相当するものですが、再代入は出来ず、単純な「数字」を割り当ててそれを「参照」するだけの仕組みです。
ですから変数に例えて説明するのは少し無理があるかもしれません。
任意のオブジェクトには、ラベル番号をつけることができます。
n m obj
対象のオブジェクト
endobj
nはオブジェクト番号 (object number)、mは世代番号 (generation number) と呼ばれます。
また、オブジェクトにオブジェクト番号と世代番号を付けたものを、間接オブジェクト (indirect object) と言います。
つまりn m obj 対象のオブジェクト endobj全体を間接オブジェクトと言います。
上記の間接オブジェクトに対する間接参照 (indirect reference) は、次のように表されます。
n m R
Rは参照 (reference) の頭文字です。
ドキュメントの中で、オブジェクト番号と世代番号の組で一意に間接オブジェクトを特定できなくてはなりません。
このエントリーでは、世代番号については説明しません。
このエントリーの範疇では、世代番号は常に0ですので、オブジェクトに番号を付けるときは
n 0 obj
対象のオブジェクト
endobj
とし、このオブジェクトに対する間接参照は
n 0 R
とするということを覚えてください。
例えば、
3 0 obj
<<
/Font <<
/F0 <<
/Type /Font
/BaseFont /Times-Roman
/Subtype /Type1
>>
>>
>>
endobj
は、フォントを定義する辞書を3番の間接オブジェクトとして宣言します。
この間接オブジェクトを参照するときは、
3 0 R
とします。
辞書の値や配列の要素を間接オブジェクトとして切り出して、それを参照することが出来ます。
例えば、上記のオブジェクトのキー/Fontに対する値を新しく4番の間接オブジェクトとして、
3 0 obj
<<
/Font 4 0 R
>>
endobj
4 0 obj
<<
/F0 <<
/Type /Font
/BaseFont /Times-Roman
/Subtype /Type1
>>
>>
endobj
としてもまったく意味は同じです。
間接参照は、配列や辞書の値などに用いることが出来ます。
例えば次の配列は、名前、数字、文字列、辞書そして間接参照 5 0 R から成る配列です。
[/test 10 (foo bar) << /baz 20 >> 5 0 R]
次のような配列はどのように読むのでしょうか。
[5 0 R 6 0 R 7 0 R]
これは、5 0 R、6 0 R そして 7 0 R という3つの間接参照から成る配列です。
もう少し、間接参照を実践的に使用した例を見てみましょう。
あるPDFファイル生成プログラムがストリームを吐いているとします。
ストリームの長さをストリームオブジェクトに書かなくてはいけませんが、ストリームの長さは全て吐き出すまで分からないとします (実装に依ります)。
こういう状況の時、ストリームの長さをとりあえず間接参照にしておき、後からそのオブジェクト番号で書き込むことができます。
5 0 obj
<<
/Length 6 0 R
>>
stream
1. 0. 0. 1. 50. 700. cm
BT
/F0 32. Tf
(Hello, world!) Tj
ET
endstream
endobj
6 0 obj
59
endobj
間接参照を理解することは、PDFのファイル構造を理解することといっても過言ではありません。
次章では、PDFのファイル構造、すなわちPDFファイルはどのように成り立っているのかについて説明します。
ファイル構造
Hello, world!
ここでは最も簡単なPDFファイル、つまりPDFのHello, world!の一例を用いて、PDFファイル全体の構成を説明します。
以下がPDFのHello, world!になります。
お好きなテキストエディタで入力し、hello.pdfという名前で保存してください。
なお、Vimをお使いの方はvim-pdfというプラグインを使用し、適切に設定すると、いい感じに補完やインデントがされると思います。
hello.pdf
%PDF-1.7
1 0 obj
<<
/Type /Catalog
/Pages 2 0 R
>>
endobj
2 0 obj
<<
/Type /Pages
/Kids [4 0 R]
/Count 1
>>
endobj
3 0 obj
<<
/Font <<
/F0 <<
/Type /Font
/BaseFont /Times-Roman
/Subtype /Type1
>>
>>
>>
endobj
4 0 obj
<<
/Type /Page
/Parent 2 0 R
/Resources 3 0 R
/MediaBox [0 0 595 842]
/Contents 5 0 R
>>
endobj
5 0 obj
<< >>
stream
1. 0. 0. 1. 50. 720. cm
BT
/F0 36 Tf
(Hello, world!) Tj
ET
endstream
endobj
xref
trailer
<<
/Size 6
/Root 1 0 R
>>
startxref
0
%%EOF
実はこれは有効なPDFではありません。
手で入力するのは少し難しい、様々な情報が欠落しています。
不完全なPDFファイルではあるものの、ファイルの構造を表すには十分な情報を提供しています。
実際、Adobe ReaderやPreview.appといった入力に寛容なPDFリーダーを使うと、上記のPDFファイルを開くことが出来ます。
しかし、完全なPDFファイルのフォーマットを見てPDFファイルを理解すべきです。
pdftkコマンドを使って不完全なPDFファイルから完全なPDFファイルを生成します。
pdftkはオープンソースなソフトウェアで、様々なプラットフォームをサポートしており、PDFファイルに対して様々な処理を行うことが出来ます。
本当に色々なことをできるコマンドなのですが、さしあたっては pdftk 入力PDF output 出力PDF で不完全なPDFを完全なPDFに変換できることを覚えておいてください。
上記のhello.pdfをpdftkで変換してみます。
$ pdftk hello.pdf output hello-out.pdf
出力されるファイルは次のようになります。
hello-out.pdf
%PDF-1.7
1 0 obj
<<
/Pages 2 0 R
/Type /Catalog
>>
endobj
2 0 obj
<<
/Kids [3 0 R]
/Count 1
/Type /Pages
>>
endobj
4 0 obj
<<
/Font
<<
/F0
<<
/BaseFont /Times-Roman
/Subtype /Type1
/Type /Font
>>
>>
>>
endobj
3 0 obj
<<
/Parent 2 0 R
/MediaBox [0 0 595 842]
/Resources 4 0 R
/Contents 5 0 R
/Type /Page
>>
endobj
5 0 obj
<<
/Length 59
>>
stream
1. 0. 0. 1. 50. 720. cm
BT
/F0 36 Tf
(Hello, world!) Tj
ET
endstream
endobj xref
0 6
0000000000 65535 f
0000000015 00000 n
0000000066 00000 n
0000000223 00000 n
0000000125 00000 n
0000000329 00000 n
trailer
<<
/Root 1 0 R
/Size 6
>>
startxref
440
%%EOF
このファイルをPDFリーダーで開いてみると、きちんとHello, world!と表示されると思います。

1つのPDFファイルは大きく分けて次の4つの要素によって成り立っています。
- ヘッダ (header)
- 本体
- 相互参照テーブル (cross-reference table)
- トレーラ (trailer)
以下ではhello-out.pdfを例にとって、4つの要素を詳しく説明していきます。
ヘッダ
PDFファイルは、2行のヘッダから始まります。
%PDF-1.7
この2行について説明します。
まず、1行目から。
%PDF-1.7
PDFのバージョンは今のところ、1.0から1.7が存在します。
厳密に言うと、このヘッダに書かれたバージョンで定義されていない要素が使われている場合、PDFリーダはその要素を読み込むのをやめることが出来ます。
しかし多くの寛容なPDFリーダは、ヘッダのバージョンに誤って古いものが書かれていても新しいバージョンとして読み込むことが多いようです。
2行目は、テキストエディタによってどういう文字が見えるかは変わってきます。
%から始まっていることから分かる通り、この行はコメントの一つです。
私の手元のhello-out.pdfでは
%\xe2\xe3\xcf\xd3
となっていました。
ファイル転送プログラムの中には、テキストファイルだと分かると勝手に改行コードを変換するものがあります。
しかし、PDFファイルは改行コードを変換されると破損してしまいます。
ファイルの最初の方を見てテキストファイルかバイナリファイルか判別しているソフトウェアに対して、このファイルがバイナリファイルであることを明確に主張するために、PDFファイルの2行目にコメントで4バイトのバイナリ文字 ('\x7f'よりも大きな文字) を置くことが推奨されています。
トレーラ
次に、トレーラ (trailer) について説明します。
トレーラはPDFファイルの最後に書かれている次の部分です。
trailer
<<
/Root 1 0 R
/Size 6
>>
startxref
440
%%EOF
PDFリーダーは、PDFファイルを最後から読みます。
それに習って最後から説明したいと思います。
ファイルの最後は次のマーカーで終わります。
%%EOF
次に、startxrefというキーワードと数字が書かれています。
startxref
440
これは、相互参照テーブルがファイルの最初から数えて何バイト目から始まるかを表しています。
試しにPDFファイルから440バイト落としてみます。
$ dd skip=440 bs=1 count=100 if=hello-out.pdf
xref
0 6
0000000000 65535 f
0000000015 00000 n
0000000066 00000 n
0000000223 00000 n
0000000125 100+0 records in
100+0 records out
100 bytes transferred in 0.000442 secs (226230 bytes/sec)
ちょうどxrefキーワードから始まる相互参照テーブルが表示されました。
これは、どんなPDFファイルでも同じです。
数MBくらいのPDFファイルを用意して、tailコマンドでファイルの最後を見て、ddでそのバイト数落としたものを表示してみてください。
$ tail -c 25 test.pdf
startxref
5103655
%%EOF
$ dd skip=5103655 bs=1 count=50 if=test.pdf
xref
...
やはりxrefキーワードからが表示されるでしょう (そうでなければそのPDFファイルは破損しています)。
実に当たり前のことですが、ほんの数十行くらいの小さなPDFファイルも、数MBもあるPDFも同じ仕組で動いていることが分かるとだんだん嬉しくなってきます。
トレーラの先頭にはtrailerキーワードと一つの辞書が書かれています。
trailer
<<
/Root 1 0 R
/Size 6
>>
ここにはドキュメントカタログが1番の間接オブジェクトであることと、後述の相互参照テーブルのエントリーの数が6個あることが記述されています。
ドキュメントカタログとはなにかについては後述します。
ファイルのドキュメントカタログの番号が分かったところで、何MBもある巨大なPDFファイルからどうやってその間接オブジェクトを見つけるのでしょうか。
賢いPDFリーダは、相互参照テーブルを使います。
相互参照テーブル
PDFファイルは、番号付けられた大量のオブジェクトと、それらに対する間接参照によって成り立っています。
PDFファイルのサイズは、数MB、数十MB、時に数百MBになることもあります。
間接参照n m Rに対して、間接オブジェクトn m objをどうやって見つけますか。
ファイルを全てメモリーにロードして探索しますか。
相互参照テーブル (cross-reference table) は、それぞれの間接オブジェクトがファイルの先頭から数えて何バイト目から始まるかを一覧にしたものです。
この仕組みによって、PDFリーダーは任意の間接オブジェクトに効率よくアクセスできるようになっています。
先ほどのhello-out.pdfの相互参照テーブルを見てみましょう。
以下に示す部分が相互参照テーブルです。
xref
0 6
0000000000 65535 f
0000000015 00000 n
0000000066 00000 n
0000000223 00000 n
0000000125 00000 n
0000000329 00000 n
上から順番に説明します。まず、相互参照テーブルはxrefキーワードから始まります。
次の行には2つの数字が書かれています。
0 6
この2つの数字は、この相互参照テーブルは何番目から何番目の間接オブジェクトのバイトオフセットを持っているかを表しています。
この例だと、0番から5番のオブジェクトの情報を持っています。
一般に
i j
の形で、i番からi + j - 1番の間接オブジェクトの情報を持っています。
続くj行が相互参照テーブルの本体になります。
今回の例だと6行あります。
0000000000 65535 f
0000000015 00000 n
0000000066 00000 n
0000000223 00000 n
0000000125 00000 n
0000000329 00000 n
順番に0番から5番の間接オブジェクトがファイルの何バイト目から始まるかを表しています。
試しに、ddコマンドでバイトオフセット分skipして表示してみます。
$ dd skip=223 bs=1 count=50 if=hello-out.pdf
3 0 obj
<<
/Parent 2 0 R
/MediaBox [0 0 595 842]
50+0 records in
50+0 records out
50 bytes transferred in 0.000276 secs (181101 bytes/sec)
$ dd skip=125 bs=1 count=50 if=hello-out.pdf
4 0 obj
<<
/Font
<<
/F0
<<
/BaseFont /Times-Rom50+0 records in
50+0 records out
50 bytes transferred in 0.000247 secs (202428 bytes/sec)
3 0 obj、4 0 objのように、間接オブジェクトの最初が表示されました。確かに各間接オブジェクトのバイトオフセットを表しているようです。
一般に、相互参照テーブルの1行は
nnnnnnnnnn ggggg u
の形をしています。
ここでnnnnnnnnnnは10桁に0埋めされた数字で、gggggは5桁に0埋めされた数字、uはfかnのいづれかです。
uがnの時、その行は使用中のエントリー (in-use entry) と言います。
この行は、間接オブジェクトが何バイト目から始まるかを表しています。
nnnnnnnnnn ggggg n
この時nnnnnnnnnnは、対象となる間接オブジェクトのバイトオフセットを表し、gggggは世代番号を表します。
uがfの時、その行をフリーエントリー (free entry) と言います。
このエントリーに対する間接オブジェクトはありません。
nnnnnnnnnn ggggg f
nnnnnnnnnnは次のフリーエントリーの番号を表し、gggggは世代番号を表します。
先ほど「0番から5番の間接オブジェクト」と言いましたが、hello-out.pdfに0番の間接オブジェクトはありません。
PDFの中で0番目のオブジェクトは特別な存在で、常にフリーなオブジェクトになっていますし、世代番号はほとんどのケースで65535になっています。
フリーエントリーの詳しい挙動については仕様書を参照してください。
このエントリーでは、複数のフリーエントリーや、世代番号、複数の相互参照テーブルなどは扱っていません。
とりあえず次の形であるということを覚えておけばよいでしょう。
xref
0 j
0000000000 65535 f
0000000aaa 00000 n
0000000bbb 00000 n
0000000ccc 00000 n
0000000ddd 00000 n
0000000eee 00000 n
...
aaaは1番の間接オブジェクトのバイトオフセット、bbbは2番の間接オブジェクトのバイトオフセット…です。
注意深い人は、行末のスペースが気になったかもしれません。
このスペースは絶対に省略してはいけません。
実はスペースと改行の2文字は、次の3通りが可能です。
" \n"
" \r"
"\r\n"
改行コードは環境によって変わってくるため、何らかの制限によって\n以外の改行コードによってPDFが作られるかもしれません。
どんな改行コードであっても各エントリーの長さを合わせるために、" \n"のようにスペースを入れることが義務付けられています。
この取り決めによって、1行の長さが20文字 (10 + 1 + 5 + 1 + 1 + 2 = 20) になることが保証されており、相互参照テーブルの中をランダムアクセスできるようになります。
例えば、n番の間接オブジェクトに対応するエントリーは、(0番のエントリーが始まるバイトオフセット) + 20 * nバイト目から始まります。
全ての相互参照テーブルをメモリーに持たなくても、任意の番号の間接オブジェクトのバイトオフセットの番号をアクセスし、そしてその間接オブジェクトにランダムアクセスできるようになっているというわけです。
またこの決まりに従っているPDFに対しては、ファイルサイズを変更することなく、相互参照テーブルの改行コードの変更を行うことが出来ます。
本体
PDFファイルの本体は、間接オブジェクトが並んだこの部分です。
1 0 obj
<<
/Pages 2 0 R
/Type /Catalog
>>
endobj
2 0 obj
endobj
5 0 obj
endobj
このPDFファイルには、間接オブジェクトが5つ存在します。
これらの間接オブジェクトの間の関係を取り持っているのが、間接参照たちです。
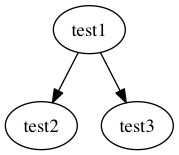
このPDFファイルの中の5つの間接オブジェクトとトレーラ辞書たちの参照関係を図に表すと、次のようになります。
 この図を参考にしながら、トップダウンで順番にオブジェクトを見て行きましょう。
まず、ファイルの最後に書かれているトレーラ辞書は次のようになっていました。
この図を参考にしながら、トップダウンで順番にオブジェクトを見て行きましょう。
まず、ファイルの最後に書かれているトレーラ辞書は次のようになっていました。
<<
/Root 1 0 R
/Size 6
>>
この/Rootには、PDFファイルの1番上の間接オブジェクトであるドキュメントカタログの番号を指定します。
ドキュメントカタログとは、PDFファイルに1つ存在し、そのPDFファイルの間接オブジェクトのグラフの中で頂点に位置するオブジェクトです。
今回ですと、ドキュメントカタログは次のようになっています。
1 0 obj
<<
/Pages 2 0 R
/Type /Catalog
>>
endobj
/Type: /Catalogを指定します。/Pages: ページツリーのオブジェクトに対応する間接参照を指定します。
ページツリーとは、簡単に言うとページの一覧を指定するオブジェクトです。
hello-out.pdfのページツリーオブジェクトは次の部分です。
2 0 obj
<<
/Kids [3 0 R]
/Count 1
/Type /Pages
>>
endobj
/Type: /Pagesを指定します。/Kids: このページツリーの直下のノードを配列で表します。/Count: このページツリーの直下にあるノードの数を表します。/Parent: 親ノードの参照を指定します。ドキュメントカタログの直下のページツリーならば指定不要です。
単純なケースでは、ページツリーオブジェクトはファイルのページオブジェクトの配列を持っています。
例えばPDFファイルが3ページあって、それぞれのページオブジェクトが3、4、5番の間接オブジェクトの場合、
2 0 obj
<<
/Kids [3 0 R 4 0 R 5 0 R]
/Count 3
/Type /Pages
>>
endobj
のようになります。
全てのページを1つのページツリーの/Kidsに指定するやり方は生成するのは簡単ですが、PDFリーダーからするとページツリーをアクセスする時の(空間)効率があまりよくありません。
そこで、ページツリーの子ノードには他のページツリーを指定することもできるようになっています。
ページツリー全体の構造をB-treeの形にすることで、効率よくそれぞれのページにアクセスできるページ構造を作ることが出来ます (このエントリーではそういうページツリー構造については説明しません)。
ページオブジェクトは次の部分です。
3 0 obj
<<
/Parent 2 0 R
/MediaBox [0 0 595 842]
/Resources 4 0 R
/Contents 5 0 R
/Type /Page
>>
endobj
このオブジェクトはPDFファイルの1ページと対応します。
ページオブジェクトの各項目は次のようになっています。
/Type: /Pageを指定します。/Parent: 親のページツリーノードを指定します。/Resources: フォントやイメージといった、ページのリソースを指定します。これを省略すると、親のページツリーノードから継承されます。/Contents: このページのコンテンツストリームに対する間接参照を指定します。/MediaBox: このページの用紙サイズをポイントで指定します。これを省略すると親ノードから継承されます。72ポイント=1インチで計算されるので、/MediaBox [0 0 595 842]はA4サイズ (210mm × 297mm) に相当します。
この他にもいくつも指定できる項目はありますが、とりあえず我々がHello, world!で指定した項目だけ説明しました。
更に様々な項目に関する説明は、『PDF構造解説』や仕様書を参照してください。
ページオブジェクトに指定されたリソース辞書は、今回の場合は次のようになっています。
4 0 obj
<<
/Font
<<
/F0
<<
/BaseFont /Times-Roman
/Subtype /Type1
/Type /Font
>>
>>
>>
endobj
今回はフォントが指定されています。
このオブジェクトによって、/F0という名前にTimes Romanを割り当てています。
ストリームから/F0という名前で該当フォントを参照することが出来ます。
ストリームオブジェクトは5番の間接オブジェクトです。
このストリームによって、ページに表示するテキストやグラフィックスを指定します。
5 0 obj
<<
/Length 59
>>
stream
1. 0. 0. 1. 50. 720. cm
BT
/F0 36 Tf
(Hello, world!) Tj
ET
endstream
endobj
ストリームには、一連の演算子 (operators) を記述することで文字やグラフィックスを描いていきます。
演算子は後置式で、引数を先に書きます。
こういう文法はPostScriptから受け継いでいます。
cm演算子は、その後に続く文字やグラフィックス全体に対して掛ける変換を指定します (センチメートルではありません)。
1. 0. 0. 1. 50. 720. cm
この6つの数字は、次のようなアフィン変換に相当します。
 つまり右方向に50ポイント、上方向に720ポイントの平行移動を表します。
この6つの数字のうち最初の4つの数字を変えると、文字を拡大縮小したり、回転させたり、歪める事ができます。
色々変化させて遊んでみてください。
つまり右方向に50ポイント、上方向に720ポイントの平行移動を表します。
この6つの数字のうち最初の4つの数字を変えると、文字を拡大縮小したり、回転させたり、歪める事ができます。
色々変化させて遊んでみてください。
BT演算子とET演算子は、これらの中がテキストであることを意味しています。
それぞれBegin TextとEnd Textの頭文字です。
引数は取りません。
BT
テキストに関する演算子たち
ET
Tf演算子はフォントとフォントサイズを指定する演算子です。
Text fontの略です。
/F0 36 Tf
ここでは、/F0フォントを使用し、36ポイントのサイズで描画することを宣言しています。
今回のケースでは、/F0フォントはリソース辞書で指定されたTimes Romanになります。
Tj演算子は文字列を表示する演算子です。何の略かは正直言って知りません。
(Hello, world!) Tj
テキストに関する演算子は他にもいくつもあります。
例えば、ここで改行して新しい文字列を表示するためにはTL演算子とT*演算子を使用します。
BT
/F0 36 Tf
40 TL
(Hello, world!) Tj T*
(The second line!) Tj T*
(The third line!) Tj T*
ET

TL (Text Leading) 演算子は、縦方向の行間オフセットを指定します。
単位はポイントです。
今回フォントサイズを36ポイントに指定しているので、それよりも少し大きい40ポイントを指定してみました。
T*演算子は次の行の先頭に移動する演算子です。
先ほどはcm演算子で文字の位置をずらしました。
cm演算子は図全体に適用される演算子ですが、もう少し細かく文字の位置を制御したいこともあります。
そういう時は、Tm (Text matrix) 演算子を使います。
変換方法はcm演算子と同じくアフィン変換です。
stream
BT
/F0 36 Tf
1. 0. 0. 1. 50. 720. Tm
(Hello, world!) Tj
/F0 46 Tf
1. 0. 0. 1. 250. 620. Tm
(The second line!) Tj
/F0 56 Tf
1. 0. 0. 1. 150. 520. Tm
(The third line!) Tj
ET
endstream
 これでもうあなたは、任意の位置に任意のサイズでテキストを配置できるようになりました。
これでもうあなたは、任意の位置に任意のサイズでテキストを配置できるようになりました。
駆け足でしたが、これでとりあえずPDFのHello, world!ファイルの内容を全て説明しました。
PDFファイルの最も小さな単位である「オブジェクト」から、間接参照、ヘッダ、トレーラ、相互参照テーブルなどを説明してきました。
次の章では、任意のテキストを与えてPDFファイルを生成するプログラムを書いてみます。
PDFを生成するプログラム
前章までは、手で書いたHello, world!ファイルを元にPDFの基礎的なオブジェクトからファイル構造まで説明してきました。
ここまで説明すると、ある程度機械的に、すなわちプログラムからPDFファイルを生成できるようになります。
この章では私が書いたテキスト→PDF変換プログラムを紹介し、そのプログラムの説明をしたいと思います。
以下が私が書いたテキストPDF変換プログラムです。
Haskellで書いてみました。
texttopdf.hsという名前で保存してください。
texttopdf.hs
{-# LANGUAGE OverloadedStrings #-}
import Data.ByteString.Lazy.Builder
import Data.List
import Data.Monoid
import System.IO (stdout)
import Text.Printf (printf)
import qualified Data.ByteString.Lazy.Char8 as BS
data PdfElem = PdfNull
| PdfBool Bool
| PdfInt Int
| PdfString BS.ByteString
| PdfName BS.ByteString
| PdfRef Int
| PdfArray [PdfElem]
| PdfDict [(BS.ByteString, PdfElem)]
| PdfStream BS.ByteString
renderElem :: PdfElem -> Builder
renderElem PdfNull = "null"
renderElem (PdfBool True) = "true"
renderElem (PdfBool False) = "false"
renderElem (PdfInt x) = intDec x
renderElem (PdfString x) = "(" <> lazyByteString (BS.concatMap escape x) <> ")"
where escape c | c `elem` ("()\\" :: String) = BS.pack ['\\', c]
| otherwise = BS.singleton c
renderElem (PdfName x) = "/" <> mconcat (map escape $ BS.unpack x)
where escape c | c < '!' || '~' < c || c == '#' = "#" <> lazyByteStringHex (BS.singleton c)
| otherwise = lazyByteString (BS.singleton c)
renderElem (PdfRef x) = intDec x <> " 0 R"
renderElem (PdfArray x) = "[" <> mconcat (intersperse " " $ map renderElem x) <> "]"
renderElem (PdfDict xs) = "<<\n" <> mconcat [ "/" <> lazyByteString x <> " " <> renderElem y <> "\n" | (x, y) <- xs ] <> ">>"
renderElem (PdfStream xs) = "<<\n/Length " <> int64Dec (BS.length xs) <> "\n>>\nstream\n" <> lazyByteString xs <> "\nendstream"
data PdfObj = PdfObj Int PdfElem
renderObj :: PdfObj -> Builder
renderObj (PdfObj n obj) = intDec n <> " 0 obj\n" <> renderElem obj <> "\nendobj\n"
data PdfVer = PdfVer Int Int
renderHeader :: PdfVer -> Builder
renderHeader (PdfVer n m) = "%PDF-" <> intDec n <> "." <> intDec m <> "\n"
<> "%" <> lazyByteString (BS.pack $ map toEnum [0xe2, 0xe3, 0xcf, 0xd3]) <> "\n"
data PdfXref = PdfXref [PdfXrefEntry]
renderXref :: PdfXref -> Builder
renderXref (PdfXref xs)
= "xref\n"
<> "0 " <> intDec (length xs) <> "\n"
<> mconcat (map renderXrefEntry xs)
data PdfXrefEntry = PdfXrefEntry Int Int PdfXrefEntryUse
renderXrefEntry :: PdfXrefEntry -> Builder
renderXrefEntry (PdfXrefEntry offset generation use)
= mconcat $ intersperse " " [ lazyByteString (BS.pack $ printf "%010d" offset),
lazyByteString (BS.pack $ printf "%05d" generation),
renderXrefEntryUse use, "\n" ]
data PdfXrefEntryUse = FreeEntry | InUseEntry
renderXrefEntryUse :: PdfXrefEntryUse -> Builder
renderXrefEntryUse FreeEntry = "f"
renderXrefEntryUse InUseEntry = "n"
data PdfTrailer = PdfTrailer Int Int Int
renderTrailer :: PdfTrailer -> Builder
renderTrailer (PdfTrailer root size startxref)
= "trailer\n"
<> renderElem (PdfDict [("Size", PdfInt size), ("Root", PdfRef root)]) <> "\n"
<> "startxref\n"
<> renderElem (PdfInt startxref) <> "\n"
<> "%%EOF\n"
data PdfFile = PdfFile PdfVer Int [PdfObj]
renderPdf :: PdfFile -> BS.ByteString
renderPdf (PdfFile ver root xs)
= header <> mconcat objects <> xref <> trailer
where header = toLazyByteString (renderHeader ver)
objects = map (toLazyByteString . renderObj) xs
offsets = map fromIntegral $ scanl (+) (BS.length header) $ map BS.length objects
xref = toLazyByteString (renderXref (PdfXref $
PdfXrefEntry 0 65535 FreeEntry : map (\n -> PdfXrefEntry n 0 InUseEntry) (init offsets)))
trailer = toLazyByteString (renderTrailer (PdfTrailer root (length xs + 1) (last offsets)))
textsToPdf :: [[BS.ByteString]] -> PdfFile
textsToPdf texts = PdfFile (PdfVer 1 7) 1 $ catalog : toppage : font : pages ++ contents
where
n = length texts
m = 4
catalog = PdfObj 1 $ PdfDict [("Type", PdfName "Catalog"),
("Pages", PdfRef 2)]
toppage = PdfObj 2 $ PdfDict [("Type", PdfName "Pages"),
("Kids", PdfArray $ map PdfRef [m .. m + n - 1]),
("Count", PdfInt n)]
font = PdfObj 3 $ PdfDict [("Font", PdfDict [("F0", PdfDict [("Type", PdfName "Font"),
("BaseFont", PdfName "Times-Roman"),
("Subtype", PdfName "Type1")])])]
pages = [ PdfObj i $ PdfDict [("Type", PdfName "Page"),
("Parent", PdfRef 2),
("Resources", PdfRef 3),
("MediaBox", PdfArray $ map PdfInt [0, 0, 595, 842]),
("Contents", PdfRef $ i + n)] | i <- [m .. m + n - 1] ]
contents = [ PdfObj i $ PdfStream $ "1. 0. 0. 1. 50. 770. cm\nBT\n/F0 12 Tf\n16 TL\n"
<> mconcat [ toLazyByteString $ renderElem (PdfString t) <> " Tj T*\n" | t <- text ]
<> "ET" | (i, text) <- zip [m + n .. m + 2 * n - 1] texts ]
splitN :: Int -> [a] -> [[a]]
splitN n = takeWhile (not . null) . unfoldr (Just . splitAt n)
main :: IO ()
main = BS.hPutStr stdout . renderPdf . textsToPdf . splitN 45 . BS.lines =<< BS.getContents
このプログラムを実行すると、標準出力にPDFが表示されます。
サンプルとしてman manの出力をPDFに変換してみます。
MANWIDTH=110 man man | col -b | runhaskell texttopdf.hs > man.pdf
man.pdfは次のようになります。
 やりました!
任意のテキストからPDFファイルを生成できるようになった時の喜びはこの上ないものです。
やりました!
任意のテキストからPDFファイルを生成できるようになった時の喜びはこの上ないものです。
ここからはtexttopdf.hsの説明をしたいと思います。
Haskellに興味が無いよ、あるいはヒント無しで自分で実装したいよという方は、スキップしてください。
まず、1行目ではOverloadedStrings言語拡張を使うことを宣言しています。
{-# LANGUAGE OverloadedStrings #-}
この宣言によって、"foo bar"といった文字列リテラルを、String以外の文字列っぽい (IsStringを継承した) 型の値としても使用できるようになります。
ByteStringといった効率のよい文字列型を扱うときは、この言語拡張が便利です。
モジュールのインポートの説明は省略します。
10行目からは、データ型の定義が始まります。
以下のコードはPDFのオブジェクトを表しています。
data PdfElem = PdfNull
| PdfBool Bool
| PdfInt Int
| PdfString BS.ByteString
| PdfName BS.ByteString
| PdfRef Int
| PdfArray [PdfElem]
| PdfDict [(BS.ByteString, PdfElem)]
| PdfStream BS.ByteString
参照もオブジェクトの1つとして実装すると統一的に扱えて便利です。
型の設計ですが、Stringではなくて比較的効率のよいByteStringを用いています。
続くrenderElem関数では、オブジェクトの表示方法を定義しています。
まず型は次のようになっています。
renderElem :: PdfElem -> Builder
Builderとは小さい文字列を集めて効率よく大きな文字列を構築するためのコンビネータです。
詳しくはライブラリーのドキュメントを参照してください。
Builderそのものは文字列というよりも文字列を構築するための関数と捉えたほうが正確ですが、OverloadedStrings言語拡張を使うと、あたかも文字列のように扱えます。
renderElem PdfNull = "null"
たった1行のコードですが、ここで何が起きているかを理解することは大切です。
OverloadedStrings言語拡張を使わずに書くと次のようになります。
renderElem PdfNull = lazyByteString $ BS.pack "null"
ここで"null" :: String、BS.pack "null" :: BS.ByteString、(lazyByteString $ BS.pack "null") :: Builderという型になっています。
OverloadedStrings言語拡張は、型をちゃんと理解した上で使用してください。
文字列の表示は次のようになっています。
renderElem (PdfString x) = "(" <> lazyByteString (BS.concatMap escape x) <> ")"
where escape c | c `elem` ("()\\" :: String) = BS.pack ['\\', c]
| otherwise = BS.singleton c
丸括弧やエスケープ文字自身をエスケープしています。これによりHello (world)は(Hello \(world\))のように変換されます。
ストリームの表示は次のように定義しました。
renderElem (PdfStream xs) = "<<\n/Length " <> int64Dec (BS.length xs) <> "\n>>\nstream\n" <> lazyByteString xs <> "\nendstream"
長さを計算して<< /Length ストリームの長さ >>という辞書を作っています。
以下のPdfObj型は、オブジェクトに番号を振った間接オブジェクトを表しています。
data PdfObj = PdfObj Int PdfElem
renderObj :: PdfObj -> Builder
renderObj (PdfObj n obj) = intDec n <> " 0 obj\n" <> renderElem obj <> "\nendobj\n"
この関数によって、間接オブジェクトは次のように表示されます。
n 0 obj
対象のオブジェクト
endobj
面倒なので世代番号は常に0としています。
ヘッダーには%PDF-M.Nといったバージョンと、4文字のバイナリ文字列をコメントで書いています。
PdfVerはPdfVer 1 7のように使います。
data PdfVer = PdfVer Int Int
renderHeader :: PdfVer -> Builder
renderHeader (PdfVer n m) = "%PDF-" <> intDec n <> "." <> intDec m <> "\n"
<> "%" <> lazyByteString (BS.pack $ map toEnum [0xe2, 0xe3, 0xcf, 0xd3]) <> "\n"
バイナリ文字は0x7fよりも大きな文字であれば何でも構いません。
相互参照テーブルPdfXrefはPdfXrefEntryの配列で、
data PdfXref = PdfXref [PdfXrefEntry]
その1つのエントリーは数字2つとエントリーが使用中かフリーかを表すフラグを持っています。
data PdfXrefEntry = PdfXrefEntry Int Int PdfXrefEntryUse
data PdfXrefEntryUse = FreeEntry | InUseEntry
表示するときは、0埋めが必要です。
renderXrefEntry :: PdfXrefEntry -> Builder
renderXrefEntry (PdfXrefEntry offset generation use)
= mconcat $ intersperse " " [ lazyByteString (BS.pack $ printf "%010d" offset),
lazyByteString (BS.pack $ printf "%05d" generation),
renderXrefEntryUse use, "\n" ]
最初の数字は10桁の0埋め、次の数字は5桁の0埋めです。
そして行末のスペースを忘れないようにしてください。
トレーラには、ドキュメントカタログのオブジェクト番号と、相互参照テーブルのエントリーの数、相互参照テーブルのバイトオフセットを渡します。
data PdfTrailer = PdfTrailer Int Int Int
renderTrailer :: PdfTrailer -> Builder
renderTrailer (PdfTrailer root size startxref)
= "trailer\n"
<> renderElem (PdfDict [("Size", PdfInt size), ("Root", PdfRef root)]) <> "\n"
<> "startxref\n"
<> renderElem (PdfInt startxref) <> "\n"
<> "%%EOF\n"
トレーラ辞書の描画には、最初の方で定義したrenderElem関数を用いることが出来ます。
1つのPDFファイルは、PDFのバージョン、ドキュメントカタログの番号と間接オブジェクトの配列によって定義しました。
data PdfFile = PdfFile PdfVer Int [PdfObj]
表示は、ヘッダーを表示し、各間接オブジェクトを表示し、相互参照テーブル、そしてトレーラを表示します。
renderPdf :: PdfFile -> BS.ByteString
renderPdf (PdfFile ver root xs)
= header <> mconcat objects <> xref <> trailer
相互参照テーブルにバイトオフセットを渡すために、BuilderをByteStringに変換して長さを計算しています。
where header = toLazyByteString (renderHeader ver)
objects = map (toLazyByteString . renderObj) xs
offsets = map fromIntegral $ scanl (+) (BS.length header) $ map BS.length objects
xref = toLazyByteString (renderXref (PdfXref $
PdfXrefEntry 0 65535 FreeEntry : map (\n -> PdfXrefEntry n 0 InUseEntry) (init offsets)))
trailer = toLazyByteString (renderTrailer (PdfTrailer root (length xs + 1) (last offsets)))
バイトオフセットを足し上げるコードは、まさにscanlがぴったり当てはまる場面です。
offsets = map fromIntegral $ scanl (+) (BS.length header) $ map BS.length objects
そしてtextsToPdf関数は、テキストからPdfFileを構築する関数です。
textsToPdf :: [[BS.ByteString]] -> PdfFile
textsToPdf texts = PdfFile (PdfVer 1 7) 1 $ catalog : toppage : font : pages ++ contents
入力の型は、1行の文字列がBS.ByteString、1ページはそれが何行かあるので[BS.ByteString]、ファイル全体では何ページかあるので[[BS.ByteString]]となっています。
間接オブジェクトの番号は次のように設計しました。
ここでnはページの数を表します。
1: ドキュメントカタログ (/Type: /Catalog)2: ページツリー (/Type: /Pages)3: リソース辞書 (フォント)4〜n + 3: ページオブジェクト (/Type: /Page)n + 4〜2 * n + 3: コンテンツストリーム
これらのコードは順番に辞書を組み立てていくだけなので説明を省略します。
以下のsplitN関数は、引数nを取って配列をその長さごとに分割していく関数です。
splitN :: Int -> [a] -> [[a]]
splitN n = takeWhile (not . null) . unfoldr (Just . splitAt n)
この関数を使ってmain関数が書かれています。
main :: IO ()
main = BS.hPutStr stdout . renderPdf . textsToPdf . splitN 45 . BS.lines =<< BS.getContents
関数結合演算子(.)が使われているときは右から読みます。
つまり、標準入力から受け取って、行ごとに分割し、さらに45行ごとに分けます。
そしてtextToPdf関数でPdfFileに変換し、renderPdf関数で文字列にしたものを、BS.hPutStr stdoutで標準出力に出力します。
これで一応ざっとtexttopdf.hsの説明をしてみました。
基本的な流れは、PDFのオブジェクトや相互参照テーブルなどをデータ型で表現し、それを描画する関数を定義するだけです。
雑に書いていくとスペースを忘れて結合してはいけないトークンがくっついてしまったり、余計な改行が入ってしまったりするので、出力を見ながら丁寧にバグを直します。
textsToPdfを書くときは、まず間接オブジェクトの番号から設計します。
上のプログラムtexttopdf.hsはHaskellで書いていますが、特にHaskellでなくては書けない難しいものではありません。
ただ単に、私が何かプログラムを書こうとし始めた時に、最初に選んでしまう言語がHaskellなだけです。
そういうわけなので、ここで練習問題を出したいと思います。
好きな言語で実装してください。
括弧の中は、私が適当に点数を振ったものです。
難易度の参考にしてください。
- あなたの好きな言語は何ですか。実装に使う言語を選んでください (5)
- その言語で、PDFの各オブジェクトのデータ構造を作ってください (10)
- そのオブジェクトを表示する関数を書いてください (20)
- 間接オブジェクトと、それを表示する関数を書いてください (5)
- ヘッダ、相互参照テーブル、トレーラーを作ってください (15)
- 1つのPDFファイル全体を表示するための関数を作ってください (15)
texttopdfを実装してください (30)
最初は、有効なPDFファイルを出力するのは難しいかもしれません。
特に、相互参照テーブルをきちんと吐くのは難しいです。
最初はpdftkコマンドで出力ファイルを完成させてもいいかもしれませんが、頑張ってきちんとしたPDFファイルを吐いて欲しいです。
有効なPDFか、そうでないかを調べる簡単な方法は、Adobe Readerでファイルを開くことです。
 ファイルを閉じるときに「保存しますか」というダイアログが出てしまったら、Adobe Readerがお気に召さないPDFファイルであるということです。
特にバイトオフセットはしっかりと計算してください。
ファイルを閉じるときに「保存しますか」というダイアログが出てしまったら、Adobe Readerがお気に召さないPDFファイルであるということです。
特にバイトオフセットはしっかりと計算してください。
- 相互参照テーブルの開始位置は正しいですか。
- 相互参照テーブルの数は正しいですか。
- 各間接オブジェクトに対するバイトオフセットは正しいですか。
- 相互参照テーブルの1行は
"nnnnnnnnnn ggggg u \n"の形になっていますか。行末のスペースを忘れていませんか。(スペースの代わりに"\r"でも構いません)
きちんとしたPDFファイルを吐けば、Adobe Readerで開いても保存ダイアログなしにファイルを閉じることが出来ます。
日本語の扱い方
この章ではPDFでの日本語の扱い方について説明します。
前章で作ったtexttopdf.hsは、残念ながらアスキー文字しか受けつけません。
最初のHello, world!に直接日本語を書いてみたり、texttopdf.hsに日本語を流し込んでも、文字化けしてしまいます。
ここでは日本語を含むPDFファイルのサンプルを例にとって、CIDフォントの指定の仕方を説明してみます。
早速ですが、以下のファイルは日本語を含むPDFファイルです。
できる限りhello.pdfを使いつつ拡張する形で書いてみました。
hello-ja.pdfという名前で保存してください。
hello-ja.pdf
%PDF-1.7
1 0 obj
<<
/Type /Catalog
/Pages 2 0 R
>>
endobj
2 0 obj
<<
/Type /Pages
/Kids [4 0 R]
/Count 1
>>
endobj
3 0 obj
<<
/Font <<
/F0 <<
/Type /Font
/BaseFont /KozMinPro6N-Regular
/Subtype /Type0
/Encoding /90ms-RKSJ-H
/DescendantFonts [6 0 R]
>>
>>
>>
endobj
4 0 obj
<<
/Type /Page
/Parent 2 0 R
/Resources 3 0 R
/MediaBox [0 0 595 842]
/Contents 5 0 R
>>
endobj
5 0 obj
<< >>
stream
1. 0. 0. 1. 50. 770. cm
BT
/F0 36 Tf
40 TL
<6162632082a082a282a4> Tj T*
<82a082a282a482a682a82082a982ab82ad82af82b1> Tj T*
<8e71894e93d0894b924396a48cdf96a2905c93d19cfa88e5> Tj T*
ET
endstream
endobj
6 0 obj
<<
/Type /Font
/Subtype /CIDFontType0
/BaseFont /KozMinPr6N-Regular
/CIDSystemInfo <<
/Registry (Adobe)
/Ordering (Japan1)
/Supplement 6
>>
/FontDescriptor 7 0 R
>>
endobj
7 0 obj
<<
/Type /FontDescriptor
/FontName /KozMinPr6N-Regular
/Flags 4
/FontBBox [-437 -340 1147 1317]
/ItalicAngle 0
/Ascent 1317
/Descent -349
/CapHeight 742
/StemV 80
>>
endobj
xref
trailer
<<
/Size 8
/Root 1 0 R
>>
startxref
0
%%EOF
このPDFファイルは相互参照テーブルなどが欠けていますので、pdftkコマンドを使ってPDFファイルを完成させます。
pdftk hello-ja.pdf output hello-ja-out.pdf
出力されたhello-ja-out.pdfを開くと次のようになります。
 見事、日本語が表示されました!
見事、日本語が表示されました!
日本語を表示するために今回指定したフォントを説明する前に、これまで指定してきたフォントを思い出してみましょう。
hello.pdfでは、フォントを次のように指定していました。
3 0 obj
<<
/Font <<
/F0 <<
/Type /Font
/BaseFont /Times-Roman
/Subtype /Type1
>>
>>
>>
endobj
/Subtypeに/Type1を指定しており、これはType 1フォントを使うことを意味しています。
Type 1フォントとは、欧文フォントのためにPostScriptで採用されていたAdobeのフォントのことです。
Type 1フォントの/BaseFontには/Times-Romanや/Times-Italic、/Helvetica、/Courierなどを使用できます。
一方で、今回作ったhello-ja.pdfで使ったフォントは次のようになっています。
3 0 obj
<<
/Font <<
/F0 <<
/Type /Font
/BaseFont /KozMinPro6N-Regular
/Subtype /Type0
/Encoding /90ms-RKSJ-H
/DescendantFonts [6 0 R]
>>
>>
>>
endobj
ここでは/Subtypeに/Type0が指定されています。
Type 0フォントとは、複数のフォント (時に複数の言語のグリフを含むことができる) をサポートするための複合フォント (composite font) を意味しています。
ここでは子孫フォントとして、6番の間接オブジェクトに書かれているフォントが/DescendantFontsに指定されています。
この指定されたフォントは次のようになっています。
6 0 obj
<<
/Type /Font
/Subtype /CIDFontType0
/BaseFont /KozMinPr6N-Regular
/CIDSystemInfo <<
/Registry (Adobe)
/Ordering (Japan1)
/Supplement 6
>>
/FontDescriptor 7 0 R
>>
endobj
このフォントは/Subtypeが/CIDFontType0となっています。
こういうフォントをCIDフォントと言います。
CIDフォントにはCID (Character IDentifier) 番号と呼ばれる数字から文字の形への対応が指定されています。
CID番号は、SJISやUTF-8と言った文字コードとは全く異なるコード体系なので、文字列の16進数表現からCID番号への変換方法を指定する必要があります。
ストリームに書かれている<6162632082a082a282a4>といった16進数表現のテキストからCID番号の列に変換するために、CMAP (Character MAP) と呼ばれるテキストコード変換テーブルを指定します。
この例ではCMAPとして/90ms-RKSJ-Hが指定されており、これはMicrosoftコードページ932 (CP932) に対応したCMAPです。
つまりここではSJISエンコーディングで16進数表現した文字列リテラルを用いています。
$ echo -n "abc あいう" | iconv -f UTF-8 -t SJIS | xxd -p
6162632082a082a282a4
$ echo -n "あいうえお かきくけこ" | iconv -f UTF-8 -t SJIS | xxd -p
82a082a282a482a682a82082a982ab82ad82af82b1
$ echo -n "子丑寅卯辰巳午未申酉戌亥" | iconv -f UTF-8 -t SJIS | xxd -p
8e71894e93d0894b924396a48cdf96a2905c93d19cfa88e5
もしSJISが嫌いでUTF-16BEで指定したいという方は、CMAPに/UniJIS-UTF16-Hを指定してください。
まずiconvとxxdコマンドでUTF-16BEエンコードした16進数表現を調べます。
$ echo -n "これはUTF-16BEです!" | iconv -f UTF-8 -t UTF-16BE | xxd -p
3053308c306f005500540046002d003100360042004530673059ff01
$ echo -n "_(:3」 ∠)_" | iconv -f UTF-8 -t UTF-16BE | xxd -p
005f0028003a0033300d002022200029005f
/Encodingを/UniJIS-UTF16-Hにして、テキストリテラルを書き換えます。
3 0 obj
<<
/Font <<
/F0 <<
/Type /Font
/BaseFont /KozMinPro6N-Regular
/Subtype /Type0
/Encoding /UniJIS-UTF16-H
>>
>>
>>
endobj
5 0 obj
<< >>
stream
1. 0. 0. 1. 50. 770. cm
BT
/F0 36 Tf
40 TL
<3053308c306f005500540046002d003100360042004530673059ff01> Tj T*
<005f0028003a0033300d002022200029005f> Tj T*
ET
endstream
endobj
これをpdftkコマンドで変換してPDFビューワで表示すると、次のようになります。
 無事、UTF-16BEでエンコードした文字列をPDFで表示することができました!
無事、UTF-16BEでエンコードした文字列をPDFで表示することができました!
hello-ja.pdfには、hello.pdfになかったFont Descriptorと呼ばれる、CIDフォントのスタイルを指定する辞書が書かれていますが、この詳細については省略します。
詳しくは『PDF構造解説』や仕様書を参照してください。
日本語を含むPDFを生成するプログラム
前章の内容を元に、先ほどのtexttopdf.hsを日本語対応させてみます。
以下のプログラムをtexttopdf-ja.hsとして保存してください。
texttopdf-ja.hs
{-# LANGUAGE OverloadedStrings #-}
import Data.ByteString.Lazy.Builder
import Data.Char (isAscii)
import Data.List
import Data.Monoid
import System.IO (stdout)
import Text.Printf (printf)
import qualified Codec.Text.IConv as IConv
import qualified Data.ByteString.Lazy.Char8 as BS
data PdfElem = PdfNull
| PdfBool Bool
| PdfInt Int
| PdfString BS.ByteString
| PdfName BS.ByteString
| PdfRef Int
| PdfArray [PdfElem]
| PdfDict [(BS.ByteString, PdfElem)]
| PdfStream BS.ByteString
renderElem :: PdfElem -> Builder
renderElem PdfNull = "null"
renderElem (PdfBool True) = "true"
renderElem (PdfBool False) = "false"
renderElem (PdfInt x) = intDec x
renderElem (PdfString x) | BS.all isAscii x = "(" <> lazyByteString (BS.concatMap escape x) <> ")"
where escape c | c `elem` ("()\\" :: String) = BS.pack ['\\', c]
| otherwise = BS.singleton c
renderElem (PdfString x) = "<" <> lazyByteStringHex (IConv.convertFuzzy IConv.Discard "UTF-8" "SJIS" x) <> ">"
renderElem (PdfName x) = "/" <> mconcat (map escape $ BS.unpack x)
where escape c | c < '!' || '~' < c || c == '#' = "#" <> lazyByteStringHex (BS.singleton c)
| otherwise = lazyByteString (BS.singleton c)
renderElem (PdfRef x) = intDec x <> " 0 R"
renderElem (PdfArray x) = "[" <> mconcat (intersperse " " $ map renderElem x) <> "]"
renderElem (PdfDict xs) = "<<\n" <> mconcat [ "/" <> lazyByteString x <> " " <> renderElem y <> "\n" | (x, y) <- xs ] <> ">>"
renderElem (PdfStream xs) = "<<\n/Length " <> int64Dec (BS.length xs) <> "\n>>\nstream\n" <> lazyByteString xs <> "\nendstream"
data PdfObj = PdfObj Int PdfElem
renderObj :: PdfObj -> Builder
renderObj (PdfObj n obj) = intDec n <> " 0 obj\n" <> renderElem obj <> "\nendobj\n"
data PdfVer = PdfVer Int Int
renderHeader :: PdfVer -> Builder
renderHeader (PdfVer n m) = "%PDF-" <> intDec n <> "." <> intDec m <> "\n"
<> "%" <> lazyByteString (BS.pack $ map toEnum [0xe2, 0xe3, 0xcf, 0xd3]) <> "\n"
data PdfXref = PdfXref [PdfXrefEntry]
renderXref :: PdfXref -> Builder
renderXref (PdfXref xs)
= "xref\n"
<> "0 " <> intDec (length xs) <> "\n"
<> mconcat (map renderXrefEntry xs)
data PdfXrefEntry = PdfXrefEntry Int Int PdfXrefEntryUse
renderXrefEntry :: PdfXrefEntry -> Builder
renderXrefEntry (PdfXrefEntry offset generation use)
= mconcat $ intersperse " " [ lazyByteString (BS.pack $ printf "%010d" offset),
lazyByteString (BS.pack $ printf "%05d" generation),
renderXrefEntryUse use, "\n" ]
data PdfXrefEntryUse = FreeEntry | InUseEntry
renderXrefEntryUse :: PdfXrefEntryUse -> Builder
renderXrefEntryUse FreeEntry = "f"
renderXrefEntryUse InUseEntry = "n"
data PdfTrailer = PdfTrailer Int Int Int
renderTrailer :: PdfTrailer -> Builder
renderTrailer (PdfTrailer root size startxref)
= "trailer\n"
<> renderElem (PdfDict [("Size", PdfInt size), ("Root", PdfRef root)]) <> "\n"
<> "startxref\n"
<> renderElem (PdfInt startxref) <> "\n"
<> "%%EOF\n"
data PdfFile = PdfFile PdfVer Int [PdfObj]
renderPdf :: PdfFile -> BS.ByteString
renderPdf (PdfFile ver root xs)
= header <> mconcat objects <> xref <> trailer
where header = toLazyByteString (renderHeader ver)
objects = map (toLazyByteString . renderObj) xs
offsets = map fromIntegral $ scanl (+) (BS.length header) $ map BS.length objects
xref = toLazyByteString (renderXref (PdfXref $
PdfXrefEntry 0 65535 FreeEntry : map (\n -> PdfXrefEntry n 0 InUseEntry) (init offsets)))
trailer = toLazyByteString (renderTrailer (PdfTrailer root (length xs + 1) (last offsets)))
textsToPdf :: [[BS.ByteString]] -> PdfFile
textsToPdf texts = PdfFile (PdfVer 1 7) 1 $ catalog : toppage : font : cidfont : fontdescriptor : pages ++ contents
where
n = length texts
m = 6
catalog = PdfObj 1 $ PdfDict [("Type", PdfName "Catalog"),
("Pages", PdfRef 2)]
toppage = PdfObj 2 $ PdfDict [("Type", PdfName "Pages"),
("Kids", PdfArray $ map PdfRef [m .. m + n - 1]),
("Count", PdfInt n)]
font = PdfObj 3 $ PdfDict [("Font", PdfDict [("F0", PdfDict [("Type", PdfName "Font"),
("BaseFont", PdfName "KozMinPr6N-Regular"),
("Subtype", PdfName "Type0"),
("Encoding", PdfName "90ms-RKSJ-H"),
("DescendantFonts", PdfArray [PdfRef 4])])])]
cidfont = PdfObj 4 $ PdfDict [("Type", PdfName "Font"),
("Subtype", PdfName "CIDFontType0"),
("BaseFont", PdfName "KozMinPr6N-Regular"),
("CIDSystemInfo", PdfDict [("Registry", PdfString "Adobe"),
("Ordering", PdfString "Japan1"),
("Supplement", PdfInt 6)]),
("FontDescriptor", PdfRef 5)]
fontdescriptor = PdfObj 5 $ PdfDict [("Type", PdfName "FontDescriptor"),
("FontName", PdfName "KozMinPr6N-Regular"),
("Flags", PdfInt 6),
("FontBBox", PdfArray $ map PdfInt [-437, -340, 1147, 1317]),
("ItalicAngle", PdfInt 0),
("Ascent", PdfInt 1317),
("Descent", PdfInt (-349)),
("CapHeight", PdfInt 742),
("StemV", PdfInt 80)]
pages = [ PdfObj i $ PdfDict [("Type", PdfName "Page"),
("Parent", PdfRef 2),
("Resources", PdfRef 3),
("MediaBox", PdfArray $ map PdfInt [0, 0, 595, 842]),
("Contents", PdfRef $ i + n)] | i <- [m .. m + n - 1] ]
contents = [ PdfObj i $ PdfStream $ "1. 0. 0. 1. 50. 770. cm\nBT\n/F0 12 Tf\n16 TL\n"
<> mconcat [ toLazyByteString $ renderElem (PdfString t) <> " Tj T*\n" | t <- text ]
<> "ET" | (i, text) <- zip [m + n .. m + 2 * n - 1] texts ]
splitN :: Int -> [a] -> [[a]]
splitN n = takeWhile (not . null) . unfoldr (Just . splitAt n)
main :: IO ()
main = BS.hPutStr stdout . renderPdf . textsToPdf . splitN 45 . BS.lines =<< BS.getContents
実行してみましょう。
$ echo "子丑寅卯辰巳午未申酉戌亥\n甲乙丙丁戊己庚辛壬癸\nあいうえお かきくけこ" | runhaskell texttopdf-ja.hs > test.pdf
PDFリーダーで開いてみます。
 日本語を含む入力を、きちんとPDFファイルにすることができました!
もう少し複雑な入力を与えてみます。
日本語を含む入力を、きちんとPDFファイルにすることができました!
もう少し複雑な入力を与えてみます。
curl -s https://ja.wikipedia.org/wiki/Portable_Document_Format | html2text | sed 's/!*\[\(.*\)\]([^)]*)/\1/g' | runhaskell texttopdf-ja.hs > wikipedia.pdf
 少し雑で横にはみ出ていたりMarkdown記法が見えていたりしますが、まったく文字化けすることなく日本語が表示されています。
もちろん、相互参照テーブルに書かれているバイトオフセットも正しいため、Adobe Readerを閉じるときに保存ダイアログが表示されることはありません。
少し雑で横にはみ出ていたりMarkdown記法が見えていたりしますが、まったく文字化けすることなく日本語が表示されています。
もちろん、相互参照テーブルに書かれているバイトオフセットも正しいため、Adobe Readerを閉じるときに保存ダイアログが表示されることはありません。
最初に書いたtexttopdf.hsとの差分を説明します。
必要なモジュールを追加しています。
import Data.Char (isAscii)
import qualified Codec.Text.IConv as IConv
もしIConvモジュールがインストールされていない時は、iconvパッケージをインストールしてください。
オブジェクトのデータ構造は変わっていませんが、PdfStringの表示方法が変わっています。
全てがアスキー文字の時はこれまでと同じ方法で描画しますが、そうでない場合はSJISに変換して16進数表現 (例えば<6162632082a082a282a4>のようなもの) で表示します。
renderElem (PdfString x) = "<" <> lazyByteStringHex (IConv.convertFuzzy IConv.Discard "UTF-8" "SJIS" x) <> ">"
このコードは、入力の文字列がUTF-8エンコードされているものと仮定しています。
lazyByteStringHexはData.ByteString.Builderの関数です。
Builderモジュールには便利な関数がいくつも用意されていますので、どうやってByteStringからBuilderに変換するんだろうと思った時は、ドキュメントをざっと眺めるとよいでしょう。
そしてtextsToPdf関数では、Type 0フォントにしたのと、CIDフォントの辞書の追加が行われています。
font = PdfObj 3 $ PdfDict [("Font", PdfDict [("F0", PdfDict [("Type", PdfName "Font"),
("BaseFont", PdfName "KozMinPr6N-Regular"),
("Subtype", PdfName "Type0"),
("Encoding", PdfName "90ms-RKSJ-H"),
("DescendantFonts", PdfArray [PdfRef 4])])])]
cidfont = PdfObj 4 $ PdfDict [("Type", PdfName "Font"),
("Subtype", PdfName "CIDFontType0"),
("BaseFont", PdfName "KozMinPr6N-Regular"),
("CIDSystemInfo", PdfDict [("Registry", PdfString "Adobe"),
("Ordering", PdfString "Japan1"),
("Supplement", PdfInt 6)]),
("FontDescriptor", PdfRef 5)]
あとFont Descriptorの辞書追加がされています。
文字列の16進数表現をちゃんと書ければ大して難しいものではありません。
先ほどの練習問題でtexttopdfを実装していただいた方は、ぜひ日本語対応させてください。
フォントのオブジェクトの追加がありますので、オブジェクト番号をずらすのを忘れないようにしてください。
グラフィックス
前章までは、PDFファイルで文字を出力する方法を紹介してきました。
この章では、線や四角や丸といったグラフィックスを表示する方法を説明します。
テキストではTjやT*といった演算子を使いましたが、グラフィックスも演算子を使って描いていきます。
PDFファイルのストリームでは、演算子とそれに対する引数で文字や絵を表現します。
例えば、次の例ではTfというフォント演算子に/F0と36という引数を渡してフォントを設定し、
TLという行間を設定する演算子に40という引数を渡してテキストの表示の設定を行い、
Tjという演算子に (Hello, world!) という引数を渡してテキストを表示しています。
/F0 36 Tf
40 TL
(Hello, world!) Tj
演算子が後置であることはもう慣れるしかありません。
グラフィックスも、グラフィックスに関する演算子があり、それらに引数を渡していくことで描画していきます。
例えば、次のようなストリームを書いてみます。
BT
/F0 24 Tf
1 0 0 1 70 770 Tm
(Line) Tj
50 650 m 150 750 l S
ET
これは、次のように表示されます。
 ここでは3つの新しい演算子が出てきました。
ここでは3つの新しい演算子が出てきました。
50 650 m 150 750 l S
まずmは移動 (move) 演算子で、描画開始の位置を変更します。
そしてlは直線 (line) 演算子で、その位置までのパスを設定します。
最後にSはストローク (stroke) 演算子で、それまでのパスを線で描画します。
グラフィックスの演算子は非常にたくさんありますが、その一部を使って次のようなPDFを書いてみます。
このエントリーのHello, world!であるhello.pdfの5番の間接オブジェクトを次のように書き換えてください。
hello-graphics.pdf
5 0 obj
<< >>
stream
BT
/F0 24 Tf
1 0 0 1 70 770 Tm
(Line) Tj
50 650 m 150 750 l S
1 0 0 1 200 770 Tm
(Square) Tj
190 650 100 100 re f
1 0 0 1 340 770 Tm
(Bezier) Tj
330 700 m
360 730 400 730 430 700 c S
1 0 0 1 480 770 Tm
(Circle) Tj
460 700 m
460 727.6 482.4 750 510 750 c
537.6 750 560 727.6 560 700 c
560 672.4 537.6 650 510 650 c
482.4 650 460 672.4 460 700 c S
1 0 0 1 70 600 Tm
(Color) Tj
1 0 0 rg
50 530 50 50 re f
0 1 0 rg
100 530 50 50 re f
0 0 1 rg
50 480 50 50 re f
1 0 1 rg
100 480 50 50 re f
0 g
1 0 0 1 200 600 Tm
(Stroke) Tj
230 580 m
260 490 l
180 550 l
280 550 l
200 490 l s
1 0 0 1 400 600 Tm
(Stroke, Fill) Tj
1 0 0 RG
1 1 0 rg
340 590 m
360 540 l
310 570 l
370 570 l
320 540 l s
390 540 m
410 490 l
360 520 l
420 520 l
370 490 l b
440 590 m
460 540 l
410 570 l
470 570 l
420 540 l b*
490 540 m
510 490 l
460 520 l
520 520 l
470 490 l f
540 590 m
560 540 l
510 570 l
570 570 l
520 540 l f*
ET
endstream
endobj
このファイルをpdftkで変換したPDFファイルは、次のように出力されます。
 絵の基本となるいくつかの構成要素で描くことができました。
絵の基本となるいくつかの構成要素で描くことができました。
少し中身の説明をします。
190 650 100 100 re f
ここでreは矩形 (rectangle) 演算子で、四角を作ります。
x, y, dx, dy という4つの引数を取り、(x, y)と(x + dx, y + dy)を対角線とする四角になります。
fは塗りつぶし (fill) を行う演算子です。
(Bezier) Tj
330 700 m
360 730 400 730 430 700 c S
cはベジェ曲線を生成する演算子です。
2つの制御点と目的の点という3つの点の座標を指定します。
その次の円の描画には、4つのベジエ曲線が使われています。
(Circle) Tj
460 700 m
460 727.6 482.4 750 510 750 c
537.6 750 560 727.6 560 700 c
560 672.4 537.6 650 510 650 c
482.4 650 460 672.4 460 700 c S
色の変更には、rgやRG演算子を使います。
1 0 0 RG
1 1 0 rg
rgは塗りつぶしに対する色で、RGはストロークに対する色です。
どちらもRGBの順で0〜1の実数を指定します。
また、gは塗りつぶしの色を灰色の0(黒)〜1(白)で指定する演算子で、Gはそのストローク版です。
ストロークの決定は、いくつも演算子があります。
340 590 m
360 540 l
310 570 l
370 570 l
320 540 l s
390 540 m
410 490 l
360 520 l
420 520 l
370 490 l b
s: パスを閉じてストロークS: パスを閉じずにストロークf: パスを閉じて塗りつぶし (全て塗りつぶす)f*: パスを閉じて塗りつぶし (奇偶規則)b: パスを閉じて塗りつぶしとストローク (全て塗りつぶす)b*: パスを閉じて塗りつぶしとストローク (奇偶規則)B: パスを閉じずに塗りつぶしとストローク (全て塗りつぶす)B*: パスを閉じずに塗りつぶしとストローク (奇偶規則)
これらの演算子を駆使すれば、様々な絵を描けるようになります。
例えば、次のようなプログラムを書いてみます (renderElem関数まではtexttopdf.hsと全く同じです)。
squares.hs
squaresPdf :: PdfFile
squaresPdf = PdfFile (PdfVer 1 7) 1 $ catalog : toppage : font : pages ++ contents
where
catalog = PdfObj 1 $ PdfDict [("Type", PdfName "Catalog"),
("Pages", PdfRef 2)]
toppage = PdfObj 2 $ PdfDict [("Type", PdfName "Pages"),
("Kids", PdfArray [ PdfRef 4 ]),
("Count", PdfInt 1)]
font = PdfObj 3 $ PdfDict [("Font", PdfDict [("F0", PdfDict [("Type", PdfName "Font"),
("BaseFont", PdfName "Times-Roman"),
("Subtype", PdfName "Type1")])])]
pages = [ PdfObj 4 $ PdfDict [("Type", PdfName "Page"),
("Parent", PdfRef 2),
("Resources", PdfRef 3),
("MediaBox", PdfArray $ map PdfInt [0, 0, 595, 842]),
("Contents", PdfRef 5)] ]
contents = [ PdfObj 5 $ PdfStream $ BS.intercalate "\n" [ BS.unwords
[ BS.pack $ printf "%.3f" $ 0.5 + 0.5 * cos (2 * pi / 16 * i * 3 / 4 :: Double),
BS.pack $ printf "%.3f" $ 0.5 - 0.5 * cos (2 * pi / 16 * i * 5 / 4),
BS.pack $ printf "%.3f" $ 0.5 - 0.5 * cos (2 * pi / 16 * i * 4 / 4),
"rg",
BS.pack $ show (round $ 250 + (200 - i * 4) * sin (2 * pi / 16 * i) :: Int),
BS.pack $ show (round $ 420 + (200 - i * 4) * cos (2 * pi / 16 * i) :: Int),
BS.pack $ show (round $ 55 - i :: Int),
BS.pack $ show (round $ 55 - i :: Int),
"re f" ] | i <- [0.0, 1.0 .. 50.0] ] ]
main :: IO ()
main = BS.hPutStr stdout $ renderPdf squaresPdf
実行してみます。
$ runhaskell squares.hs > squares.pdf
PDFビューワーで開くと、カラフルな四角が螺旋状に並んだ絵が表示されます。
 色を指定する
色を指定するrg演算子と、矩形パスを作るre、塗りつぶしを行うfしか使っていませんが、プログラムで位置を決めたりサイズを変更していくことで面白い絵が描かれました。
また、次のようにプログラムの最後の部分を変更してみます (Data.Complexをインポートしてください)。
contents = [ PdfObj 5 $ PdfStream $ BS.intercalate "\n"
[ printStroke (hilbert 0 (80 :+ 770) (0 :+ 40) (0 :+ 1))
, printStroke (hilbert 1 (140 :+ 755) (14 :+ 28) (0 :+ 1))
, printStroke (hilbert 2 (215 :+ 705) (30 :+ 35) (0 :+ 1))
, printStroke (hilbert 3 (315 :+ 610) (50 :+ 40) (0 :+ 1))
, printStroke (hilbert 4 (430 :+ 460) (80 :+ 40) (0 :+ 1)) ] ]
printStroke [] = ""
printStroke (x:xs) = BS.intercalate "\n" (showPoint "m" x : map (showPoint "l") xs) <> " S"
showPoint s x = BS.pack (printf "%.3f" (realPart x)) <> " " <> BS.pack (printf "%.3f" (imagPart x)) <> " " <> s
hilbert :: Int -> Complex Double -> Complex Double -> Complex Double -> [Complex Double]
hilbert n x0 x1 x2 | n == 0 = [x0 - y1 - y2, x0 + y1 - y2, x0 + y1 + y2, x0 - y1 + y2]
| otherwise = hilbert (n - 1) (x0 - y1 - y2) y2 (-x2)
<> hilbert (n - 1) (x0 + y1 - y2) y1 x2
<> hilbert (n - 1) (x0 + y1 + y2) y1 x2
<> hilbert (n - 1) (x0 - y1 + y2) (-y2) (-x2)
where y1 = x1 / 2; y2 = x1 * x2 / 2
実行してPDFファイルを生成すると、次のようにヒルベルト曲線が描画されます。
 パスを描画しているだけですが、ほんの120行程度のプログラムでこれだけ様々な絵をPDFに吐けるようになると、楽しくなってきます。
後はあなたが何をしたいか (幾何学的な模様を描きたいのか、あるいは他のフォーマットからの変換を行いたいのか) ということにかかってきます。
テキストと線を組み合わせて、例えばページの上下に横線を引いたり、枠線を作って領収書のようなものを作ることもできるでしょう。
自由な発想でPDFのグラフィックスを楽しんでください。
パスを描画しているだけですが、ほんの120行程度のプログラムでこれだけ様々な絵をPDFに吐けるようになると、楽しくなってきます。
後はあなたが何をしたいか (幾何学的な模様を描きたいのか、あるいは他のフォーマットからの変換を行いたいのか) ということにかかってきます。
テキストと線を組み合わせて、例えばページの上下に横線を引いたり、枠線を作って領収書のようなものを作ることもできるでしょう。
自由な発想でPDFのグラフィックスを楽しんでください。
PDFを読むプログラム
この章では、PDFファイルを読むプログラムを書いてみます。
本音を言うと、PDFに書かれているテキストを抽出するプログラム pdftotext を実装したいところです。
しかし、パーサーを書き始めるとどうしてもコードの書き方が言語やライブラリに依存してしまいます。
そこで、ここで紹介するプログラムでは、相互参照テーブルを読み込んで、それぞれの間接オブジェクトの最初表示するだけにします。
これまで何度も繰り返してきたとおり、PDFファイルは何MB、何十MBにもなります。
そういうファイルを一気にメモリーに読み込むのは賢いやり方ではありません。
ファイルの中の間接オブジェクトにランダムアクセスするための方法が、相互参照テーブルです。
PDFリーダーは、おおよそ次のようにファイルを読みます。
- 最初の行からPDFのバージョンを調べる
- ファイルの最後を読み、相互参照テーブルが何バイト目から始まるかを調べる
- トレーラを見て、ドキュメントカタログが何番かを調べる
- 相互参照テーブルから、ドキュメントカタログが何バイト目から始まるかを調べる
- ドキュメントカタログの本体にアクセスして、オブジェクトをパースしてページ構造を解釈していく
- 間接参照があるときは、相互参照テーブルから対象となる間接オブジェクトが何バイト目から始まるかを調べて、アクセスする
相互参照テーブルによって、PDFリーダーは必要なオブジェクトを必要なときにロードすることが出来ます。
例えば、
1 0 obj
<<
/Type /Catalog
/Pages 2 0 R
>>
endobj
2 0 obj
<<
/Type /Pages
/Kids [4 0 R 5 0 R 6 0 R]
/Count 3
>>
endobj
3 0 obj
<<
/Font << 略 >>
>>
endobj
4 0 obj
<<
/Type /Page
/Parent 2 0 R
/Resources 3 0 R
/MediaBox [0 0 595 842]
/Contents 7 0 R
>>
endobj
5 0 obj
<<
/Type /Page
/Parent 2 0 R
/Resources 3 0 R
/MediaBox [0 0 595 842]
/Contents 8 0 R
>>
endobj
6 0 obj
<<
/Type /Page
/Parent 2 0 R
/Resources 3 0 R
/MediaBox [0 0 595 842]
/Contents 9 0 R
>>
endobj
7 0 obj
<< /Length ... >>
stream
% とても大きなstream
endstream
endobj
8 0 obj
<< /Length ... >>
stream
% とてもとても大きなstream
endstream
endobj
9 0 obj
<< /Length ... >>
stream
% とてもとてもとても大きなstream
endstream
endobj
このようなページとコンテンツがあるとします。
ストリームにはPDFの各ページのコンテンツ (や他のありとあらゆる情報) が書き込まれているため、一般にストリームは大きくなることが多いです。
今、PDFビューワーが1ページ目を表示しているとします。
2番目の間接オブジェクトを見れば、1ページ目のページオブジェクトは4番、さらにコンテンツのオブジェクトは7番と分かります。
従って、他のページのコンテンツのオブジェクト、8番・9番の間接オブジェクトは読み込む必要はありません。
PDFファイルが何十MBもあったとしても、優秀なPDFビューワーは任意のページを一瞬で開くことができるでしょう。
また、ビューワーを3ページ目までスクロールした時、9番の間接オブジェクトをメモリーに読み込みますが、逆に7番の間接オブジェクトは不要になるので、メモリーから解放します。
サムネイル表示などをすると、多くのストリームを読み込む必要が有るため、非同期でロードするように実装されているかもしれません。
とにもかくにも、きちんとしたPDFリーダーを実装するのはかなりややこしそうです。
そこで今回は、相互参照テーブルを読み込んで、それぞれの間接オブジェクトの最初の行を表示するだけのプログラムを書いてみました。
以下がそのプログラムです。
readpdf.hs
import Control.Monad
import Data.Functor ((<$>))
import System.Environment
import System.IO
xrefIndex :: Handle -> IO (Maybe Integer)
xrefIndex handle = do
hSeek handle SeekFromEnd (-100)
contents <- replicateM 100 (hGetChar handle)
return $ do
("%%EOF":xrefIdxStr:"startxref":_) <- Just $ reverse $ words contents
return $ read xrefIdxStr
printEachObj :: Handle -> Integer -> IO ()
printEachObj handle xrefIdx = do
hSeek handle AbsoluteSeek xrefIdx
xref <- words <$> hGetLine handle
case xref of
["xref"] -> do
xrefLen <- read <$> (!!1) <$> words <$> hGetLine handle
putStrLn $ unwords [ "cross-reference table length:", show xrefLen ]
replicateM_ xrefLen $ do
lineWords <- words <$> hGetLine handle
case lineWords of
[ objOffset, _, "n" ] -> do
posn <- hGetPosn handle
hSeek handle AbsoluteSeek (read objOffset)
putStrLn =<< hGetLine handle
hSetPosn posn
_ -> return ()
_ -> putStrLn "Error on reading cross-reference table"
main :: IO ()
main = do
filename <- head <$> getArgs
handle <- openBinaryFile filename ReadMode
xrefIdxOpt <- xrefIndex handle
case xrefIdxOpt of
Just xrefIdx -> do
putStrLn $ unwords [ "cross-reference table starting index:", show xrefIdx ]
printEachObj handle xrefIdx
_ -> print "Error on extracting cross-reference table starting index"
hClose handle
このプログラムを実行してみます。
$ runhaskell readpdf.hs hello-out.pdf
cross-reference table starting index: 440
cross-reference table length: 6
1 0 obj
2 0 obj
3 0 obj
4 0 obj
5 0 obj
きちんと間接オブジェクトの最初が表示されました。
気持ちがいいですね。
たいていのPDFファイルでうまくいくはずです。
もし、うまくいかないなら、そのファイルは壊れているか、あるいはもう少し複雑な相互参照テーブルの形をしています (そういうケースはこのエントリーでは扱いません)。
$ runhaskell readpdf.hs broken.pdf
cross-reference table starting index: 116
Error on reading cross-reference table
とりあえず、ファイルが壊れていることを疑ってみます。
pdftkコマンドを使って修復してみます。
$ pdftk broken.pdf output fixed.pdf
$ du -m fixed.pdf
22 fixed.pdf
$ runhaskell readpdf.hs fixed.pdf
cross-reference table starting index: 19699815
cross-reference table length: 123846
1 0 obj
2 0 obj
3 0 obj
4 0 obj
5 0 obj
6 0 obj
7 0 obj
8 0 obj
9 0 obj
10 0 obj
...
22MもあるPDFファイルでも、間接オブジェクトのリストが綺麗に表示されました。
ファイルの全てをロードしているのではなく、ランダムアクセスして必要な分だけロードしているため高速に動作します。
もしこの方法でうまくいかなければ、そのPDFはこのエントリーで説明している範囲外の技術を使って保存されている可能性があります。
例えば、相互参照ストリーム (cross-reference streams) などです (このエントリーでは扱いません)。
順番にコードの説明をしましょう。
xrefIndex、 printEachObj そしてmainの3つの関数が定義されています。
xrefIndex関数は、ファイルハンドルを受け取って、相互参照テーブルが始まるバイトオフセットを返す関数です。
まず型の設計をしてみましょう。
この関数にはファイルハンドルを渡すので、Handle ->と書きます。
そして、返したいバイトオフセットは数字なので、Integerを返せばいい気がしますが、こういう処理は様々な理由により失敗しうるのでMaybe Integer、ファイルを読み込むというIOが絡むのでIO (Maybe Integer)を返します。
xrefIndex :: Handle -> IO (Maybe Integer)
型の設計は出来ました。
関数の本体を書いていきます。
まず、ファイルの後ろから100バイト戻ったところに移動 (fseek相当) して、100バイト取り込みます。
hSeek handle SeekFromEnd (-100)
contents <- replicateM 100 (hGetChar handle)
この2行のコードは、System.IOモジュールのドキュメントを読めば書くことが出来ます。
そして、contentsを単語毎に分割し、後ろから2番目の単語を数字にして返します。
最後が"%%EOF"、後ろから3番目がstartxrefである必要があるので、Maybe Monadのdoでパターンマッチさせています。
return $ do
("%%EOF":xrefIdxStr:"startxref":_) <- Just $ reverse $ words contents
return $ read xrefIdxStr
1番最後の単語が%%EOF以外だったり、3番目がstartxref以外だったり、あるいはファイルが全体で1単語だったりすると、Nothingが返ってきます。
%%EOFの後に100個の改行があるみたいな意地悪なPDFファイルでもNothingが返ってくるでしょう。
次の関数printEachObjは、相互参照テーブルのバイトオフセットをもらって、各間接オブジェクトの1行目を表示します。
まず、読み込み位置を相互参照テーブルの最初に設定します。
printEachObj :: Handle -> Integer -> IO ()
printEachObj handle xrefIdx = do
hSeek handle AbsoluteSeek xrefIdx
そして、1行読み込んでxrefキーワードかどうかチェックします。
そうでなければ失敗です。
xrefキーワードの後は、必ず改行文字があることが仕様で決められています。
xref <- words <$> hGetLine handle
case xref of
["xref"] -> do
_ -> putStrLn "Error on reading cross-reference table"
次に、相互参照テーブルの中のエントリーがいくつあるかを読み取ります。
xrefLen <- read <$> (!!1) <$> words <$> hGetLine handle
putStrLn $ unwords [ "cross-reference table length:", show xrefLen ]
インデックスアクセスする時は、ちゃんと十分な長さあるかチェックして失敗系も書かなくてはなりませんが、とりあえず雑に書いています。
そして、各行を読み込んで間接オブジェクトのバイトオフセットobjOffsetを調べ、その位置に移動 (fseek相当) して、1行表示して、位置を戻しています。
replicateM_ xrefLen $ do
lineWords <- words <$> hGetLine handle
case lineWords of
[ objOffset, _, "n" ] -> do
posn <- hGetPosn handle
hSeek handle AbsoluteSeek (read objOffset)
putStrLn =<< hGetLine handle
hSetPosn posn
_ -> return ()
main関数は、コマンドライン引数からファイル名を読み込み、
main :: IO ()
main = do
filename <- head <$> getArgs
対象となるファイルを読み込みモードで開き、
handle <- openBinaryFile filename ReadMode
相互参照テーブルのバイトオフセットを読み込み、
xrefIdxOpt <- xrefIndex handle
それが成功したら、そのバイトオフセットを先ほどのprintEachObj関数に渡します。
case xrefIdxOpt of
Just xrefIdx -> do
putStrLn $ unwords [ "cross-reference table starting index:", show xrefIdx ]
printEachObj handle xrefIdx
_ -> print "Error on extracting cross-reference table starting index"
そして、最後にファイルハンドルを閉じて、終わりです。
hClose handle
プログラムの各行がそれぞれ重要な役割を果たしています。
全体でも50行を切っており、かなりコンパクトに書かれていることが分かるでしょう。
今回もHaskellで書いてしまいましたが、やはり特にHaskellでなくては書けないプログラムではありません。
ファイルを読み込む手段があり、fseek相当の関数があるならば、どんな言語でも書けるはずです。
ここで練習問題を出したいと思います。
好きな言語で実装してみてください。
- あなたの好きな言語は何ですか。実装に使う言語を選んでください (5)
- その言語で、ファイルの最後の100バイトを読み込み表示するプログラムを書いてください。数百MBのファイルでも高速に動作することを確認してください (10)
- 最後の単語が
%%EOFの時にのみ、最後から2番目の単語を数字として解釈して表示してください (10)
- 先ほどの数字を使って、相互参照テーブルの最初の行を表示してください。その行は
xrefでしたか (15)
- 相互参照テーブルの各行に対して、そのバイトオフセット位置に移動して、間接オブジェクトの1行目を表示するプログラムを作ってください (15)
- 各間接オブジェクトを
endobjまで表示してください (途中に文字列として(endobj)があっても動くようにしてください) (20)
- トレーラーを読み込んで、ドキュメントカタログを表示するだけのプログラムを書いてください (25)
PDFファイルを読む練習問題は、以上です。
上で私が示したプログラムでは、最後の2つができていません。
オブジェクトを読み込んでパースするのは難易度が高いと思います。
ここまで実装したら、PDFをもっと自由に扱えるプログラムを書きたくなってくるでしょう。
/Kidsを辿ってページリストを構築、ストリームをパースして表示されているテキストを表示してくれるpdftotextの実装、2つのPDFファイルを読み込んで結合してくれるプログラム…
そして、様々なPDFファイルに対応したPDFリーダー・ライターを実装できたら、PDFファイルを扱うプログラマーとして一人前と言っていいでしょう (私は全然その域まで到達していません。これから頑張って色々と実装していきたいと思います)。
その第一歩として、このエントリーを読んで頂けたのならば、これ以上嬉しい事はありません。
あとがき
PDFファイルの基本的な要素は単純明快ですし、ファイル構造を理解することも難しくありません。
PDFファイルは今後もしばらくは広く使われるでしょうし、一度ファイル構造を覚えてしまえば長く役立つ知識になります。
PDFの仕様は公開されていますし、なんといってもこの世の中にはPDFファイルはあふれています。
それにもかかわらず、PDFファイルは理解し難いものだと思われている気がします。
プログラマーとてPDFファイルは理解し得ない謎のバイナリフォーマットと考えている人が多いのではないでしょうか。
多くの人に、PDFファイルのファイル構造を正しく理解して欲しい、その一心でこのエントリーを書きました。
PDFのファイル構造の理解への第一歩を踏み出す一助になればと思います。
PDFのファイル構造の全てを理解することは非常に時間がかかります。
私も全てを理解しているわけではありません。
PDFの仕様書は750ページもあり、全てを頭に入れるのは大変です。
このエントリーは (タイトルにも書いているように)、PDFのファイル構造の入門をお伝えしたに過ぎません。
例えば、次のような内容はこのエントリーには書いていません。 (私もまだ全然理解できていないなくて、記事を書けないということもあります)
どれも重要な内容ですし、一般に広く使われています。
本気でPDFビューワーを作ろうと思ったら、これらに関してはもちろん理解しなくてはなりません。
何らかの形式からPDFを生成するプログラムも、フルスクラッチで作り始めてしまったら様々な要求に対応するのが大変になっていくでしょう。
PDFの構造を理解していき、様々なPDFに対する操作を行えるようになることは、とても楽しいことです。
思い出してください。
PDFのオブジェクトすら理解していなかった時は、PDFファイルをテキストエディタで開いても、謎のバイナリ列を前に絶望していたでしょう。
それが様々なPDFを生成できるようになり、また既存のPDFファイルも解析できるようになる喜びは、この上ないものです。
しかし、何らかのかっちりしたもの ー 例えば仕事でPDF扱わなくてはいけない時など ー を作るときは、まず信頼のおけるライブラリを探すべきでしょう。
このエントリーは、PDFのほんの入口を覗いたに過ぎませんし、今からちゃんとしたPDFライブラリを1から作るのは多くの時間が必要です。
例えそうだとしても、入門レベルすら知らないのと、自前でPDFを生成したことまである人では、やはりPDFに対する理解は全然違います。
このエントリーは、最速でPDFの様々な概念を理解していただくため、若干言葉の定義や仕様が不正確ではない部分があります。
さらなるPDFについての理解を求める人は、『PDF構造解説』の購入をお薦めします。
また、正確な言葉の定義や仕様については、
アドビシステムズより公開されている仕様書を参照してください。
私も、この記事を書くために一通り目を通しました。
はてなでは、たとえ業務と関係ない技術だとしても、自分自身が仕組みを理解していない技術に対し、積極的に調査して仕組みを理解し、実際にコードを書き、あるいは得られた知見を伝え広めたいと思っている、そんな好奇心旺盛で教えたがりなエンジニアを募集しています。
hatenacorp.jp