あらすじ
ソフトウェアの構造を概観するには
あなたは、大きなソフトウェアを目にした時、何をしますか? ファイルが何十、何百もある時、どこから読みますか?
ソフトウェアが巨大になると、そのコードの構造を把握するのは難しくなります。 特にプロジェクトに入りたての人にとって巨大なコードベースを一目で理解することは難しく、細かなタスクをこなしていく中で徐々に「どこに何が書いてあるか」を理解していくしかありません。 ソフトウェアによってはモデルとコントローラ、データベースとビューと言った具合にコードが分かれており、これくらいの分類はディレクトリ名を見れば理解できるかもしれません。 しかしそのようなざっくりとしたコードの分類が分かったところで、ソフトウェアの構造を理解したと言えるとは思えません。 例えばモデルの中のファイルが互いにどういう関係になっているのかということは、実際にファイルを読んでみないと分かりません。
オブジェクト指向のパラダイムを持つ言語において、クラス図 (あるいは一般にUMLモデル) を用いるのは、ソフトウェアを理解するための有効な手段です。 クラスの継承関係を図にすることで、そのソフトウェアにどういうクラスがあってどういう関係なのかを一目で見て理解することができます。 そのプロジェクトに新しく入った人にとっても、クラス図を最初に見せてくれたらコードを読みやすくなるでしょう。 設計段階でそういった図を用いることもありますし、既存のコードを解析時してクラス図を生成する製品もあります。
しかし、私たちが知りたいのはクラス間の関係ばかりではありません。 オブジェクト指向ではない言語もたくさんあります。
私たちが大きなソフトウェアを前にして知りたいのは、「何らかのもの」の間の依存関係ではないでしょうか。
「何らかのもの」というのは、例えばファイルであったり、パッケージであったり、クラスやオブジェクト、あるいはモジュールであったり、とにかくそういうものです。
例えば、C言語であればファイルの間は#includeというキーワードでファイルが関連していますので、ファイルの間の依存関係をクラス図のように描画できたら嬉しいと思います。
Goであればpackageというキーワードでそのファイルが所属するパッケージを記述し、importというキーワードでパッケージ間が関連します。
Haskellであれば、モジュール間の依存関係を描画できたら、抽象的なコードを読み始める手がかりになるかもしれません。
ファイルであれパッケージであれモジュールであれ、「何らかのまとまったコード」の間の依存関係を簡単に抽出できたら、大きなソフトウェアであってもコードの構造を概観できるのではないでしょうか。
正規表現で大雑把に抽出しよう
さぁ、ソフトウェアの汎用的な依存関係解析ツールを作りましょう。 あなたならどういう設計にしますか? Javaのコードからクラス図を生成する製品の延長で考えると、対応したい言語のパーサーを搭載し、指定されたコードの言語によってうまいことパースして依存関係を抜き出すというものを思い付くでしょう。 しかし、次のように言われたらどうしますか?
「Cなら#includeで、Rubyならrequireだから。あと最近はサーバーサイドJavaScript流行ってるらしいし、JavaScriptのrequireにも対応してね。スマホアプリも作るからSwiftも。あとmakeもよく使うしMakefileのtargetの依存関係も解析できるようになってると嬉しいね。あと個人的にはHaskellが好きなのでHaskellにも対応しておいてね。」
あらゆる言語にきちんと対応してあげたい。そんなことを言っていたら、そのツールのコードは泥沼になるでしょう。
色々な言語に対応させていくと、まずそのコードは肥大化して手に負えなくなるでしょう。 そして、新たに流行っている言語に対応するよう要求され、「パーサーすらないのに無理だよ…」と、つらい思いをします。 また、抽出したいものは言語によって一つではありません。 ある言語ではモジュールの依存関係も見たいし、クラスの継承関係も見たいし、時には関数レベルの依存関係を見たいという要求も出てくるかもしれません。 言語ごとに設定したいことが出てくると、ツールのオプションもどんどん増えていきます。
もっとシンプルに考えましょう。 難しいことをあれこれ考えだすと、夢は膨らみますがツールは現実になりません。 ある程度は汎用的にし、かつ妥協点を見つけて「これ以上は難しいのでこのツールでは対応できません」と言うことにしましょう。 このような汎用的かつミニマムなツールの設計は、どうすればいいのでしょうか*1。
私たちが抽出したいのは、
#include "test.c"
のtest.cの部分であり、あるいは
var bar = require('foo').bar;
のfooの部分であり、あるいは
import Data.Foo
のData.Fooの部分です。
こういうファイルが依存しているファイル、あるいはモジュールを、ざっくり抜き出したいわけです。
#includeやrequire、importなど様々ありますが、とにかく決まったキーワードの後の部分を抜き出したいのです。
これらはどれも、ユーザーに正規表現を1つ指定してもらったら、抜き出せますよね。
例えばCのコードに対しては/#include +"(\S+)"/の正規表現でファイルをなめれば、キャプチャーした文字列が、そのファイルが読み込んでいるファイルの名前になります。
あるいは/require\('(\S+)'\)/や、/import +(\S+)/などを使えば、他の言語でも使えるでしょう。
もちろん、完璧な正規表現などありません。
先ほどの/#include +"(\S+)"/は、
// #include "foo.c"
のようにコメントアウトしても誤ってマッチしてしまいそうです。
これくらいなら最初に^をつけて、/^#include +"(\S+)"/のようにすればよいでしょう。
でもC言語では#とincludeの間に空白文字を置けますし、空白文字はスペースだけではなくタブ文字もあります。
# include "foo.c"
よろしい、ならば/^\s*#\s*include\s+"(\S+)"/でどうでしょうか。
この正規表現では、行末に次のようなコメントがあるとだめですね。
#include "foo.c"/*コメント"*/
では/^\s*#\s*include\s+"([^"]+)"/のようにするとどうでしょうか。
#include /* コメント */ "foo.c" /* コメント "hoge.c" */
こうなると、簡単な正規表現で対応できそうにありません。 いくらでも意地悪な例は作れるのです。
しかし、私たちが解析したいコードはもっと現実的なコードです。 仕事で扱っている、あるいはOSSの、わりとスタイルの整ったコードをもっと大雑把に解析したいのです。 上記のような異常なスタイルのコードはまずないのです。 本当に正確に解析しなくてはいけないという要求があるならば、きちんと動くパーサーを用意しなくてはいけませんが、先程述べたように特定の言語に特化したツールになってしまうか、あるいは多くの言語のパーサーを搭載し始めてツールが肥大化してしまいます。 そうではなくてもっと手軽に依存関係を抜き出したいのです。
というわけで、作ったのがrexdepです。
rexdep
多くの言語に利用できる汎用的な依存関係抽出ツール rexdep を作成し、GitHubでソースコードを公開しています。
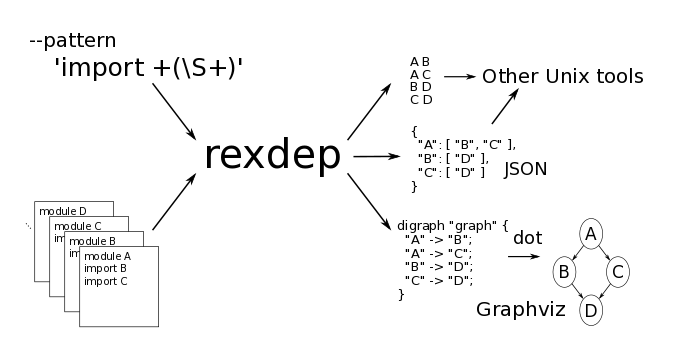
名前の由来は "Roughly EXtract DEPendency relation"、すなわち「大雑把に依存関係を抽出する」です。 大雑把の意味は既に述べたとおりです。 上記のような試行錯誤やあるところで妥協点を見つけた上で、これくらいのインターフェースがあれば幅広い要求に答えられるだろうとして作りました。
インストールはとても簡単です。 Homebrewをお使いの方は、次のコマンドですぐにインストールできます。
$ brew install itchyny/tap/rexdep
WindowsやDebian、FreeBSDなどをお使いの方には、GitHubのReleasesページにてバイナリーを用意しておりますので、ダウンロードしたzipやtar.gzを解凍してバイナリーをパスの通ったディレクトリに移動してください。
rexdepは次のようなことができます。
- ユーザーが指定した正規表現 (
--pattern PATTERN) をファイルの各行にマッチさせていき、正規表現がキャプチャーした文字列を依存先のファイルやモジュールと判断します。 - ディレクトリが指定された時は
--recursiveオプションをつけることで、ディレクトリ以下の全てのファイルを解析します。 - スペース区切り、あるいはCSV、dot、JSONのフォーマットで出力できます。特にdotのフォーマットで出力し、dotコマンドで依存関係を画像にするというのが想定している使い方です。
dotというのはグラフ (折れ線グラフのグラフではなく、ネットワークとしてのグラフ) を記述するための言語の名前であり、かつその言語で書かれたスクリプトを画像に変換するコマンドの名前です。 Graphvizをインストールすることをおすすめします。
本来なら最初は丁寧に使い方を説明するところですが、先にそれなりに大きなソフトウェアを解析してどのようなものが見えるのかを紹介します。
例えば、gitのソースコードを落としてきてヘッダーの依存関係を見たいとします。 rexdepとdotコマンドがあれば、次のように簡単にヘッダーの依存関係を抽出することができます。
$ git clone --depth 1 https://github.com/git/git $ rexdep --pattern '^\s*#include\s*[<"](\S+)[>"]' --format dot ./git/*.h | dot -Tpng -o git.png
クリックすると全体像を見ることができますが、大きい画像なのでモバイル環境の方はご注意ください。
 ファイル間の依存関係を見ると、どのファイルがユーティリティーっぽいファイルで、どのファイルが機能を実装しているファイルかというのが見えてきます。
ファイル間の依存関係を見ると、どのファイルがユーティリティーっぽいファイルで、どのファイルが機能を実装しているファイルかというのが見えてきます。
次の例は、pandocというHaskell製の文書変換ツールのソースコードを解析したものです。
$ git clone --depth 1 https://github.com/jgm/pandoc $ rexdep --pattern '^\s*import +(?:qualified +)?([[:alnum:].]+Pandoc[[:alnum:].]*)' --module '^module +([[:alnum:].]+Pandoc[[:alnum:].]*)' --format dot --recursive ./pandoc/src/ | dot -Tpng -o pandoc.png
こちらもリンク先は大きな画像なのでご注意ください。
 モジュールの依存関係を概観できるようになると、どのモジュールが重要そうかなんとなく掴めるので、ソースコードを読む手がかりになります。
モジュールの依存関係を概観できるようになると、どのモジュールが重要そうかなんとなく掴めるので、ソースコードを読む手がかりになります。
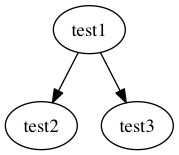
ここからは、基本的な使い方を抑えながら、分かりやすいサンプルを用いて使い方を説明します。 次のような小さなテキストファイルがあるとします。
$ cat test1 import test2 import test3
rexdepの--patternに、importの後の単語を抜き出すような正規表現を指定してみます。
$ rexdep --pattern 'import +(\S+)' test1 test1 test2 test1 test3
右側は依存先のファイルで、左側は依存元になります。
--formatオプションで出力のフォーマットをdot言語にします。
$ rexdep --pattern 'import +(\S+)' --format dot test1 digraph "graph" { "test1" -> "test2"; "test1" -> "test3"; }
これをdotコマンドにパイプをつなぐだけで、次のような画像が得られます。
$ rexdep --pattern 'import +(\S+)' --format dot test1 | dot -Tpng -o test.png
もちろん、rexdepに複数のファイルを指定すると、それら全てを読み込んで依存関係を出力してくれます。
$ rexdep --pattern 'import +(\S+)' --format dot test{1,2,3,4} digraph "graph" { "test1" -> "test2"; "test1" -> "test3"; "test2" -> "test4"; "test3" -> "test4"; } $ rexdep --pattern 'import +(\S+)' --format dot test{1,2,3,4} | dot -Tpng -o test.png
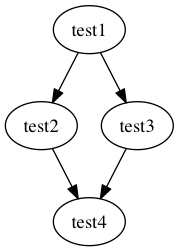
これが最も基本的な使い方です。
rexdepが受け取った正規表現は、全てGo言語のregexp.Compileでコンパイルされます。
Go言語の正規表現のシンタックスは公式のリファレンスもしくはgo doc regexp/syntaxを参照してください。
デフォルトでは、依存元の名前はファイル名になります。 これはC言語では便利ですが、他の言語ではあまり便利ではないことがあります。 例えば次のような2つのファイルがあるとします。
$ cat Foo.hs module Foo where import Bar import System.Directory $ cat Bar.hs module Bar where import System.IO
--patternの指定だけだと、次のようになります。
$ rexdep --pattern 'import (\S+)' Foo.hs Bar.hs Foo.hs Bar Foo.hs System.Directory Bar.hs System.IO
Foo.hsの依存先はBarになりましたが、依存元はBarではなくファイル名のBar.hsになってしまっています。
そこで、rexdepには--moduleというオプションがあります。
このケースだと、次のようにすればうまくいきます。
$ rexdep --pattern 'import (\S+)' --module 'module (\S+)' Foo.hs Bar.hs Foo Bar Foo System.Directory Bar System.IO
きちんとFoo -> Bar -> System.IOのような関係がとれました。
この--moduleオプションは、それを見つけてから有効になります。
例えば、hogeという名前で次のようなファイルがあるとします。
import Bar module Foo import Baa import Baz module Qux import Quux import Quuz
先ほどと同じコマンドを試してみます。
$ rexdep --pattern 'import (\S+)' --module 'module (\S+)' hoge hoge Bar Foo Baa Foo Baz Qux Quux Qux Quuz
一番最初の依存元はファイル名になっていますね。 モジュールを見つけたら、そのモジュール名が依存元になります。 これは、そういうものとさせてください。
もう少し難しいパターンを紹介します。 次のようなファイルがあるとします。
$ cat sample AはBとCとDに依存している BはCとDに依存している CはDに依存している Dは何にも依存していない
このサンプルファイルに対しては、次のようなコマンドで依存関係を抽出できます。
$ rexdep --pattern '^(?:[A-Z]+)(?:は([A-Z]+))?(?:と([A-Z]+))?(?:と([A-Z]+))?に依存している' --module '^([A-Z]+)は.*依存している' sample A B A C A D B C B D C D
この例は文章っぽいので、あまり応用できるように思えないかもしれません。 しかし、例えば次のような例を考えるときには役立つでしょう。
$ cat Makefile all: clean build build: deps go build install: deps go install deps: go get -d -v . clean: go clean .PHONY: build deps clean $ rexdep --pattern '^[^.][^:]+: +(\S+)(?: +(\S+))?(?: +(\S+))?' --module '^([^.][^:]+):' Makefile all build all clean build deps install deps
見事、Makefileからtargetの依存関係を抜き出すことができました。 また、次のようなユースケースも考えられます。
$ cat sample.js FooBarApp .service('FooService', [ '$rootScope', '$location', '$window', function(...) { }]) .service('BarService', [ '$location', 'FooService', function(...) { }]) .directive('FooDirective', [ '$location', 'FooService', function(...) { }]) .controller('BarController', [ '$scope', '$location', '$window', 'BarService', function(...) { }]); $ rexdep --pattern "^ *\\.(?:service|directive|controller).*\\[ *'([^']+)'(?:, *'([^']+)')?(?:, *'([^']+)')?(?:, *'([^']+)')?" --module "^ *\\.(?:service|directive|controller)\\('([^']+)'," sample.js FooService $location FooService $rootScope FooService $window BarService $location BarService FooService FooDirective $location FooDirective FooService BarController $location BarController $scope BarController $window BarController BarService
こういう例だと、どうしても正規表現も複雑になってしまいます。 正規表現で解析できるレベルの限界という感じもします。 しかし、特定の言語やパラダイムをターゲットにした解析ツールよりも、遥かに柔軟に要求に答えられることを理解していただけると思います。
rexdepは以上では紹介しなかった--startと--endというオプションも持っています。
これらのオプションをうまく使うことで、依存関係を抽出する範囲を制御し、例えばGo言語のimportからパッケージの名前を抽出したり、Scalaのオブジェクトの継承関係を抽出したりすることもできます。
ここでは具体的な例は述べませんが、GitHubのREADME.mdを参照し、いい感じにコードから狙ったものを抽出できる正規表現を見つけてください。
まとめ
ソフトウェアの中の依存関係を大雑把に抽出するツール rexdep を作りました。
基本的に--patternの引数という一つの正規表現によって、多くの言語のimport文に対応しています。
この設計の裏には、オブジェクト指向言語におけるクラス図を生成するような、ASTレベルで解析してきっちりとした出力を行うツールの存在があります。 このようなツールは、特定の言語やパラダイムに特化し、クラスの継承関係のみならずメソッドの型のような深い解析をして多くの情報を見せてくれます。
一方、私はきちんとした出力をすることは諦め、ユーザーが一つ正規表現を与えてくれれば、多くの言語でimport文を大雑把に抽出できることに気がつきました。 これによって、rexdepはオブジェクト指向言語のみならず様々な言語のファイルやモジュールの間の依存関係をビジュアライズすることができるようになりました。 新しく流行りだした言語やマイナーな言語でも、正規表現を一つ与えさえすれば、ソフトウェアの構造を概観できると思います。
rexdepは大雑把です。 いじわるなコメントや、絶対に正規表現では対応できないようなパターンはいくらでも存在します。
しかし、ソフトウェアの構造を大雑把に概観し、素早くビジュアライズしたいという要求のもとでは、rexdepのアプローチは一つの有効な手段だと考えています。 ソフトウェアの構造を概観できるようになると、新しくチームに入った人に理解してもらいやすくなるばかりではなく、依存関係があるべきでない箇所が見つかったり、リファクタリングの指針に使えると考えています。
「正規表現でコードなめたら、ある程度ならコードを概観できるなぁ」というアイディアは、一年以上前から私の中にありました。 最初はmikutterのコードを読みたいと思ったものの、Rubyは全くの初心者なので、せめてコードの依存関係でもと思って描画してみたのが始まりでした。 当時はzshでスクリプトを書きましたが、使い捨てのスクリプトで汎用的にする気はありませんでした。 しかし、仕事に就き大きなソフトウェアを目にすると、ソフトウェアの構造をざっくり把握する必要性を感じ始めました。 また、他のエンジニアの方がPerlのコードを静的解析して作ったクラス図を元にリファクタリングしているのを聞いて、昔やったアイディアをいい感じに組み立てなおして形にしたいと考えました。 色々と試行錯誤をし、zshのスクリプトでmockを作りながらあれこれ考えた末、最終的に正規表現を引数でもらう今の形のrexdepに収まったというわけです。 また、仕事でGoを触り始めたのと、個人的にGoで一つまとまったcliツールを作りたかったということ、マルチプラットフォーム向けにバイナリーで配布したかったので、Goで実装しました。
正規表現で依存関係を大雑把に抽出する。 そのシンプルなアイディアから生まれたrexdepを、ぜひお使い下さい。
はてなでは、ぼんやりとしたアイディアをコードにできて、要求を正確に分析した上で実現可能でかつ破綻しにくい設計ができ、また作ったものを公開し世に広めて、多くの人に使ってもらいたい、そんな意欲的でかつ能動的なエンジニアを募集しています。 hatenacorp.jp
*1:こういう思想は、拙作のlightline.vimと通じるものがあります。他のプラグインの関数を使ってしまうと、新しく流行ったプラグインにも対応しなくてはいけません。lightline.vimは、他のプラグインとの連携はユーザーに委ねています。いい感じに他のプラグインとインテグレーションして万人に便利になることを諦めたのです。こうすることによって、lightline.vim自体の責務を最小限にしてコードが肥大化するのを回避し、かつユーザーが使うインターフェースを汎用的にしてパワーユーザーの要求にも応えたのです。詳しくはlightline.vim作りました - プラグインの直交性についてをご参照ください。